RocksDB简介
RocksDB是一个高性能读写、可扩展、嵌入式、持久化、可靠、易用及可定制的键值数据库。内部采用LSM-Tree数据,支持高吞吐的写入和快速的范围查找。
RocksDB是一种嵌入式数据库,2012年基于谷歌的LevelDB分叉而来,最初由Dhruba Borthakur在Facebook创建,目的是提高服务器工作负载性能。目前,RocksDB由Meta开发和维护。
使用RocksDB存储引擎的分布式数据库有许多,其中一些比较著名的包括:
1. TiDB:TiDB 是一款开源的分布式关系型数据库,兼容 MySQL 协议。它将 RocksDB 用作底层存储引擎,并通过 Raft 协议实现高可用和分布式一致性。
2. CockroachDB:CockroachDB 是一个分布式 SQL 数据库,支持水平扩展和强一致性。它使用 RocksDB 作为存储引擎来管理数据的持久化。
3. YugabyteDB:YugabyteDB 是一个开源的高性能分布式 SQL 数据库,支持 PostgreSQL 和 Cassandra 的接口。它采用 RocksDB 作为存储引擎,提供强一致性和线性扩展能力。
4. ScyllaDB:ScyllaDB 是一个高性能的 NoSQL 数据库,兼容 Apache Cassandra。它在某些场景下也可以选择使用 RocksDB 作为存储引擎,以提升性能。
5. MyRocks:MyRocks 是基于 MySQL 的一个分支实现,直接使用 RocksDB替换InnoDB存储引擎 来提高写入性能和压缩比。这使得 MyRocks 成为一个支持高吞吐量和低延迟的存储解决方案。
RocksDB有几个特点:
- 嵌入式数据库,所谓嵌入式即它没有独立的进程,而是集成到应用中和应用共享内存资源
- 它没有内置服务器,无法通过网络进行远程访问
- 它不是分布式的,它不提供分区容错性、高可用及分片机制
- RocksDB是以Key-Value形式存储数据,Key、value都是任意长度的字节数组(Byte array),因此他没有数据类型
- 适合写大于读的场景,支持大量数据存储,写更快、存储空间占用更小(紧凑存储)
如何才能进行硬件的快速读写
快速读写硬件的性能主要取决于如何有效利用内存和磁盘的 I/O 特性。
磁盘在随机IO和顺序IO之间的差异:
• 随机 I/O:HDD 通过磁头读取数据,随机访问需要磁头移动和盘片旋转,导致较高的寻道时间和旋转延迟。
• 顺序 I/O:顺序访问数据时,磁头只需很少的移动或不移动,数据连续读取,减少了寻道时间和旋转延迟,性能明显提高。
InnoDB 的写入机制

如图所示:
- 第一步:在内存中新增undolog用于MVCC(多版本事务控制),方便事务的后续回滚,如果执行失败或事物提交会标记为待删除。
- 第二部:在buffer pool缓冲池中找到要修改的行所在页(MySQL中数据操作最小单位),如果找不到会报缺页,等待从磁盘中进行加载
- 第三部:顺序写入Redo log buffer,会按照策略进行同步或者异步镜像系统刷盘
- Checkpoint: 后台异步线程会定时或者达到刷盘条件时,触发Double writer机制,保证异步离散写的数据一致性(mysql 16K的页对应系统4个4K的页)
从上面第二部可以看出,Mysql其实是原地写,即要找到原来的记录进行修改,如果缓存池中频繁报缺页,写入性能势必会收到影响
接下来我们看看RocksDB它是如何做的?它是如何利用磁盘的顺序写同时还保证了写的性能的
LSM-Tree(Log Structure Merge tree)
RocksDB采用的是LSM树(Log-Structure merge Tree)的数据结构, 它是将所有的数据修改(增删改)都记录内存的顺序memtable和磁盘顺序的日志文件中(Write-Ahead Log,WAL)中,在由异步“Flush”流程,将内存的memtable慢慢归并成L0、L1、12…Ln的磁盘文件中。如下图所示:

LSM-Tree 的顶层保存在内存中,包含最近插入的数据。较低层存储在磁盘上,编号从 0 到 N。0 级 (L0) 存储从内存移动到磁盘的数据,1 级及以下存储较旧的数据。当某个层变得太大时,它会与下一个层合并,而下一个层通常比前一个层大一个数量级。

为了更好地理解 LSM 树的工作原理,让我们仔细看看写入数据的过程。
写入数据
预写日志
无论是在进程意外崩溃退出还是计划内重启时,其内存中的数据都会丢失。为了防止数据丢失,保证数据的持久化,除了 MemTable 之外,RocksDB 会将所有更新写入到磁盘上的预写日志(WAL,Write-ahead log)中。这样,在重启后,数据库可以回放日志,进而恢复 MemTable 的原始状态。
WAL 是一个只允许追加的文件,包含一组更改记录序列。每个记录包含键值对、记录类型(Put / Merge / Delete)和校验和(checksum)。与 MemTable 不同,在 WAL 中,记录不按 key 有序,而是按照请求到来的顺序被追加到 WAL 中。
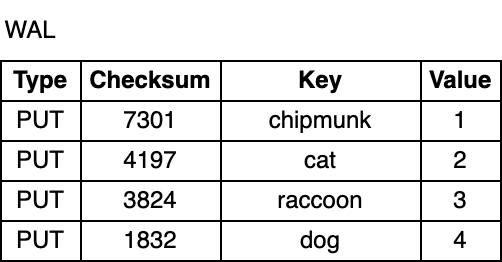
Memtable
RocksDB会将内存划分为大小相近的memtable进行存储对对数据的增删改查操作,通常在memtable内部是一个SkipList结构,按Key顺序记录了当前key在当前这个memtable中最新的操作记录。当memtable满了时,会将当前active memtable改成immutable memtable(不可变的memtable),并同时生成一个新的active memtable供后续的写操作使用。
内存表的默认大小为 64MB。
例如添加以下键值
db.put("chipmunk", "1")
db.put("cat", "2")
db.put("raccoon", "3")
db.put("dog", "4")
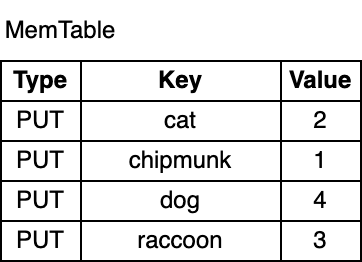
我们看到,尽管chipmunk是第一个插入的,但在MemTable中仍然排在cat之后,因为他是按key的顺序排序的,顺序排序的好处可以加快我们的检索效率(如用二分法、跳表、红黑树)
Flush
RocksDB 使用一个专门的后台线程定期地把不可变的 MemTable 从内存持久化到磁盘。一旦刷盘(flush)完成,不可变的 MemTable 和相应的 WAL 就会被丢弃。RocksDB 开始写入新的 WAL、MemTable。每次刷盘都会在 L0 层上产生一个新的 SST 文件。该文件一旦写入磁盘后,就不再会修改。
RocksDB 的 MemTable 的默认基于跳表实现。该数据结构是一个具有额外采样层的链表,从而允许快速、有序地查询和插入数据。有序性使得 MemTable 刷盘时更高效,因为可以直接按顺序迭代键值对顺序写入磁盘。将随机写变为顺序写是 LSM-Tree 的核心设计之一。

SSTable(Sorted String Table)
SST 文件包括从 MemTable 刷盘而来的键值对,并且使用一种对查询友好的数据格式来存储。SST 是 Static Sorted Table 的缩写(其他数据库中也称为 Sorted String Table)。它是一种基于块( block) 的文件格式,会将数据切成固定大小的块(默认为 4KB)进行存储。RocksDB 支持各种压缩 SST 文件的压缩算法,例如 Zlib、BZ2、Snappy、LZ4 或 ZSTD 算法。与 WAL 的记录类似,每个数据块中都包含用于检测数据是否损坏的校验和。每次从磁盘读取数据时,RocksDB 都会使用这些校验和进行校验。
SST 文件由几个部分组成:首先是数据部分,包含一系列有序的键值对。key 的有序性可以让我们对 其进行增量编码,也即,对于相邻的 key ,我们可以只存其差值而非整个 key。
尽管 SST 中的 kv 对是有序的,我们也并非总能进行二分查找,尤其是数据块在压缩过后,会使得查找很低效。RocksDB 使用索引来优化查询,存储在紧邻数据块之后的索引块。Index 会把每个 block 数据中最后一个 key 映射到它在磁盘上的对应偏移量。同样地,index 中的 key 也是有序的,因此我们可以通过二分搜索快速找到某个 key。
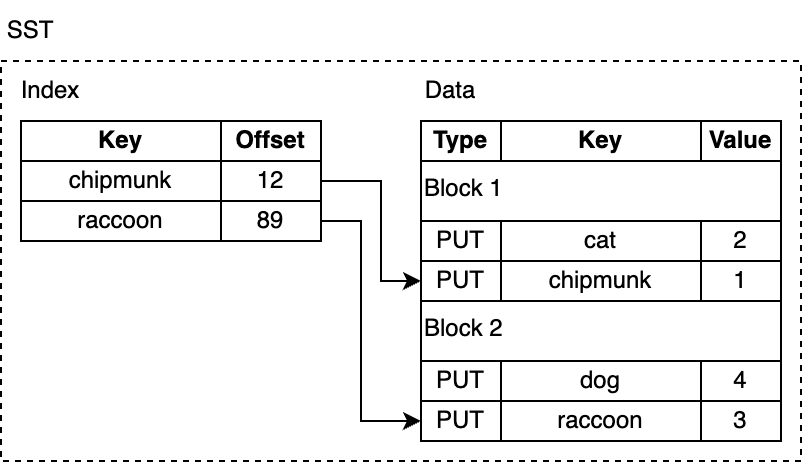
Compaction(压缩)
到现在为止,一个功能完备的键值存储引擎讲完了。但如果这样直接上生产环境,会有一些问题:空间放大(space amplifications)和读放大(read amplifications)。空间放大是存储数据所用实际空间与逻辑上数据大小的比值。假设一个数据库需要 2 MB 磁盘空间来存储逻辑上的 1 MB 大小的键值对是,那么它的空间放大率是 2。类似地,读放大用来衡量用户执行一次逻辑上的读操作,系统内所需进行的实际 IO 次数。作为一个小练习,你可以尝试推演下什么是写放大。
现在,让我们向数据库添加更多 key 并删除当中的一些 key:
db.delete("chipmunk")
db.put("cat", "5")
db.put("raccoon", "6")
db.put("zebra", "7")
// Flush triggers
db.delete("raccoon")
db.put("cat", "8")
db.put("zebra", "9")
db.put("duck", "10")
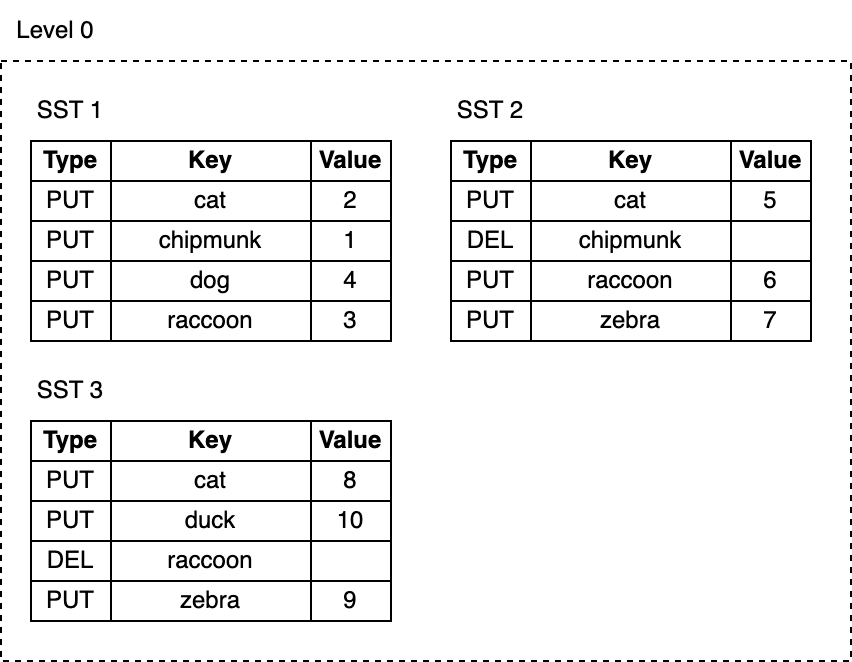
随着我们的不断写入,MemTable 不断被刷到磁盘,L0 上的 SST 文件数量也在增长:
- 删除或更新 key 所占用的空间永远不会被回收。例如,
cat这个 key 的三次更新记录分别在 SST1,SST2 和 SST3 中,而chipmunk在 SST1 中有一次更新记录,在 SST2 中有一次删除记录,这些无用的记录仍然占用额外磁盘空间。 - 随着 L0 上 SST 文件数量的增加,读取变得越来越慢。每次查找都要逐个检查所有 SST 文件。
RocksDB 引入了压实( Compaction )机制,可以降低空间放大和读放大,但代价是更高的写放大。Compaction 会将某层的 SST 文件同下一层的 SST 文件合并,并在这个过程中丢弃已删除和被覆盖的无效 key。Compaction 会在后台专用的线程池中运行,从而保证了 RocksDB 可以在做 Compaction 时能够正常处理用户的读写请求。

Leveled Compaction 是 RocksDB 中的默认 Compaction 策略。使用 Leveled Compaction,L0 层中的不同 SST 文件键范围会重叠。L1 层及以下层会被组织为包含多个 SST 文件的序列,并保证同层级内的所有 SST 在键范围上没有交叠,且 SST 文件之间有序。Compaction 时,会选择性地将某层的 SST 文件与下一层的 key 范围有重叠 SST 文件进行合并。
举例来说,如下图所示,在 L0 到 L1 层进行 Compaction 时,如果 L0 上的输入文件覆盖整个键范围,此时就需要对所有 L0 和 L1 层的文件进行 Compaction。

而像是下面的这种 L1 和 L2 层的 Compaction,L1 层的输入文件只与 L2 层的两个 SST 文件重叠,因此,只需要对部分文件进行 Compaction 即可。
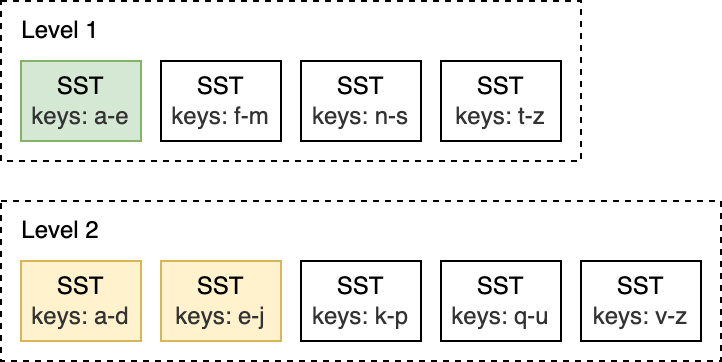
当 L0 层上的 SST 文件数量达到一定阈值(默认为 4)时,将触发 Compaction。对于 L1 层及以下层级,当整个层级的 SST 文件总大小超过配置的目标大小时,会触发 Compaction 。当这种情况发生时,可能会触发 L1 到 L2 层的 Compaction。从而,从 L0 到 L1 层的 Compaction 可能会引发一直到最底层级联 Compaction。在 Compaction 完成之后,RocksDB 会更新元数据并从磁盘中删除 已经被 Compcated 过的文件。
注:RocksDB 提供了不同 Compaction 策略来在空间、读放大和写放大之间进行权衡。
看到这里,你还记得上文提过 SST 文件中的 key 是有序的吗?有序性允许使用 K 路归并算法逐步合并多个 SST 文件。K 路归并是两路归并的泛化版本,其工作方式类似于归并排序的归并阶段。
读取数据过程
使用持久化在磁盘上不可变的 SST 文件,读路径要比写路径简单很多。要找寻某个 key,只需自顶而下遍历 LSM—Tree。从 MemTable 开始,下探到 L0,然后继续向更低层级查找,直到找到该 key 或者检查完所有 SST 文件为止。
以下是查找步骤:
- 检索 MemTable。
- 检索不可变 MemTables。
- 搜索最近 flush 过的 L0 层中的所有 SST 文件。
- 对于 L1 层及以下层级,首先找到可能包含该 key 的单个 SST 文件,然后在文件内进行搜索。
搜索 SST 文件涉及:
- (可选)探测布隆过滤器。
- 查找 index 来找到可能包含这个 key 的 block 所在位置。
- 读取 block 文件并尝试在其中找到 key。
这就是全部所需步骤了!看看这个 LSM-Tree:

根据待查找的 key 的具体情况,查找过程可能在上面任意步骤提前终止。例如,在搜索 MemTable 后,key “cat” 或 “chipmunk” 的查找工作会立即结束。查找 “raccoon” 则需要搜索 L1 为止,而查找根本不存在的 “manul” 则需要搜索整个树。
RocksDB的优缺点
RocksDB是一种高性能的嵌入式键值存储引擎,具有以下优点和缺点:
优点:
-
高性能:RocksDB采用LSM-Tree数据结构,具有高效的写入性能,同时使用Bloom Filter和Block Cache等技术,具有高效的读取性能,可以在高负载和大规模数据情况下保持高性能。
-
灵活性:RocksDB具有丰富的配置选项和插件机制,可以根据不同的应用场景和需求进行灵活的调整和扩展,例如支持不同的压缩算法、过滤器和存储引擎等。
-
可扩展性:RocksDB支持水平扩展和自动容错,可以通过添加新的节点,来提高系统的吞吐量和存储容量。
-
多语言支持:RocksDB支持多种编程语言,包括C++、Java、Python等,可以方便地在不同的应用场景下使用。
-
稳定性:RocksDB是Facebook开发的开源项目,已经经过多年的稳定运行和优化,具有高可靠性和稳定性
缺点:
-
内存占用较高:由于RocksDB需要维护多个LSM树,需要占用较多的内存空间,对于内存资源较为紧张的环境可能不太适用。
-
存储空间浪费:RocksDB的LSM-Tree结构需要占用更多的磁盘空间,对于存储资源较为紧张的环境可能造成浪费。
-
部署复杂:RocksDB需要根据实际的应用场景进行配置和调整,需要专业的系统管理员进行管理和维护。
-
写放大问题:RocksDB的LSM-Tree结构可能会造成写放大问题,即需要更多的磁盘I/O来保证数据的一致性和可靠性。
-
不支持分布式事务:RocksDB是一种嵌入式存储引擎,不支持分布式事务,需要借助其他组件(如TiDB)来实现分布式事务。
RocksDB 为什么快
RocksDB 的高性能源于其 LSM-Tree 架构,同时还有很多技术优化,如高效的写入路径、多级 Compaction 策略、高效的缓存机制、并发优化以及读取优化等,如下:
1. LSM-Tree(Log-Structured Merge-Tree)架构:
• 高效写入:LSM-Tree 将所有写入操作首先写入内存中的 MemTable,然后顺序写入 WAL(Write-Ahead Log),最后在后台合并到 SSTables(Sorted String Tables)。这种设计避免了随机写入磁盘,提高了写入吞吐量。
• 后台合并:通过后台的 Compaction 过程,将多个 SSTables 合并成更大的 SSTables,进一步优化磁盘 I/O 并减少读放大。
2. 多级 Compaction 策略:
• Level Compaction:将 SSTables 分层存储,通过逐层合并减少读放大和磁盘空间的浪费。
• Universal Compaction:适用于需要快速写入的大型数据集,通过更灵活的合并策略进一步优化写性能。
3. 高效的缓存机制:
• Block Cache:缓存 SSTables 的数据块,减少磁盘读取,提高读性能。
• Table Cache:缓存 SSTables 的元数据,快速定位数据块,减少不必要的磁盘 I/O。
4. 高效的写入路径:
• WAL(Write-Ahead Log):顺序写入日志,确保数据持久性,减少写入延迟。
• MemTable:内存中的写入缓冲区,快速写入数据,然后批量刷入磁盘。
5. 高并发和低延迟:
• 多线程 Compaction:利用多线程进行后台合并,充分利用多核 CPU,提高并发性。
• Fine-grained Locking:细粒度锁机制,减少锁争用,提高并发性能。
6. 优化的读取路径:
• Bloom Filters:使用布隆过滤器快速过滤不存在的键,减少不必要的磁盘 I/O。
• Prefix Seek:前缀查找优化,快速定位相关键值对。
通过这些优化,RocksDB 提供了卓越的性能和可靠性,成为许多高性能应用的首选存储引擎。
适合场景
1. 高写入吞吐量的应用:
• 由于 LSM-Tree 的架构和高效的写入路径,RocksDB 非常适合需要高写入吞吐量的应用,如日志收集、时间序列数据存储等。
2. 低延迟的实时应用:
• RocksDB 的多级缓存和高效的读写路径使其适合低延迟的实时应用,如实时分析、实时消息处理等。
3. 高并发访问的应用:
• RocksDB 的细粒度锁机制和多线程 Compaction 支持高并发访问,非常适合高并发的在线服务,如社交媒体平台、电子商务网站等。
4. 嵌入式存储需求:
• 由于其嵌入式设计,RocksDB 非常适合作为大型系统的嵌入式存储引擎,如数据库系统的存储引擎、分布式存储系统等。
5. 大规模数据存储:
• RocksDB 的多级 Compaction 策略和高效的磁盘空间管理使其适合大规模数据存储应用,如数据仓库、大数据分析平台等。


