你有没有遇到过这种情况:问AI一个问题,它自信满满地给了你一大段详细回答,结果你一查发现全是瞎编的?这就是AI圈子里臭名昭著的"幻觉"问题——模型编造事实还理直气壮,比你女朋友生气时的逻辑还离谱。
作为每天和AI打交道的程序员,我对这个问题真是又爱又恨。爱它能快速给出答案,恨它时不时给我挖坑。直到最近,OpenAI在2025年9月4日发表了一篇重磅论文,终于系统性地解释了为什么AI总爱"一本正经地胡说八道"。

这篇题为《Why Language Models Hallucinate》的论文,是OpenAI罕见的纯技术分析文章(要知道他们平时要么发产品要么发API,很少这么坦诚地分享研究细节)。核心结论其实很简单:现在的AI训练和评估机制,本质上是在鼓励模型猜答案,而不是承认自己不知道。
先看看AI的"幻觉"有多离谱
OpenAI给"幻觉"下了个定义:"模型自信地生成不真实答案的情况。"说白了就是——一本正经地胡说八道。
为了证明这个问题有多普遍,研究团队做了个有趣的实验。他们问了几个主流AI模型同一个问题:“Adam Tauman Kalai博士的博士论文标题是什么?”(这位是论文的第一作者,有点自黑精神)。结果你猜怎么着?

ChatGPT(GPT-4o)、DeepSeek和Llama这三个模型,给出了三个截然不同的答案,而且——没有一个是对的。这还不算完,他们又问了Adam的生日,结果更离谱:

某个开源模型在三次尝试中,给出了"03-07"、“15-06"和"01-01"三个日期——没错,连1月1日这种元旦节都出来了,而正确答案其实是在秋季(具体日期未公开)。最气人的是,每个答案后面都跟着"确定”、"无疑"这样的词,自信得让你无法怀疑。
问题出在"考试机制"上
为什么会这样?OpenAI的研究指出了一个很反常识的结论:不是AI太笨,而是我们的"考试"方式有问题。
现在评估AI模型,基本上只看"准确率"——答对了给分,答错了不给分,不答也不给分。这就好比考试时,选择题你不会做也必须蒙一个,因为空着肯定没分,蒙还有25%的机会对。长期下来,模型自然就学会了"瞎猜"。
OpenAI做了个对比实验,他们训练了两个模型:

左边的gpt-5-thinking-mini模型被训练得更"谦逊",不确定就弃权;右边的o4-mini则是传统训练方式。结果很有意思:
- 准确率:22% vs 24%(传统模型略高)
- 错误率(幻觉率):26% vs 75%(传统模型高太多)
- 弃权率:52% vs 1%(传统模型几乎从不弃权)
也就是说,传统模型为了那2%的准确率提升,付出了错误率增加近3倍的代价!这就像一个学生考试时,为了多拿2分,把所有不会的题都瞎蒙了一遍,结果错得一塌糊涂。
更麻烦的是,现在行业里的评估基准几乎都有这个问题:
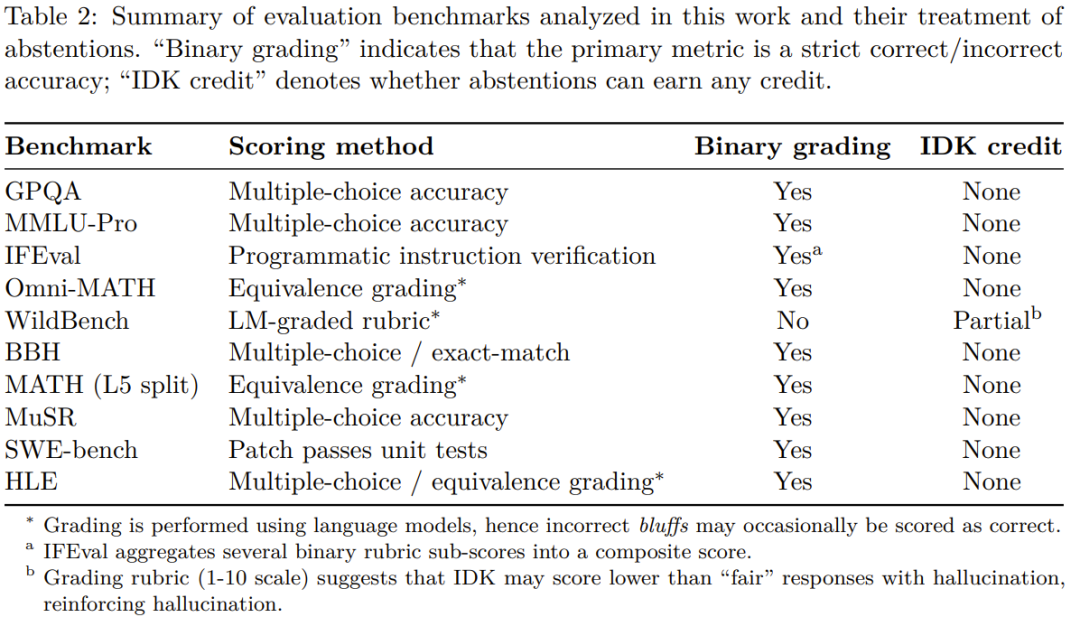
OpenAI分析了10种主流评估基准(GPQA、MMLU-Pro等),发现绝大多数都只看准确率,不鼓励模型表达不确定性。这种"唯分数论"的评估体系,逼着所有AI模型都去学"应试技巧"——哪怕瞎猜也要给个答案,反正错了不扣分。
从根源解决:让AI学会说"我不知道"
那么怎么解决这个问题?OpenAI提出了个简单但有效的方案:改革评估机制,鼓励AI说"我不知道"。
具体来说就是:
- 答对了给满分
- 明确说"不知道"给部分分(比如1/3分)
- 答错了扣分(惩罚)
这就像某些考试的"倒扣分"规则,瞎猜的风险远大于收益,模型自然就会变得更谨慎。其实人类社会早就懂这个道理——为什么医生看病总是很谨慎?因为误诊的代价远大于说"这个症状我需要进一步检查"。
OpenAI自己已经开始这么做了。他们最新的模型幻觉率明显降低,而且据TechCrunch报道,OpenAI最近重组了团队,原模型行为团队负责人Joanne Jang启动了一个叫oai Labs的新项目:

这个团队专注于"发明和设计人们与AI协作的新界面原型",很可能就包括让AI更坦诚表达不确定性的交互方式。
对我们普通人有什么影响?
作为普通用户,这件事其实和我们关系很大:
- 别轻信AI的"肯定":看到"无疑"、“确定”、"显然"这类词时,反而要多留个心眼,最好自己验证一下
- 学会追问来源:问AI问题时,可以加一句"你的信息来源是什么?",现在有些模型已经能提供引用了
- 期待更诚实的AI:未来的AI可能会更像一个谨慎的顾问,而不是全知全能的神——这其实是好事,毕竟真实世界中,承认局限比假装全知更可靠
最后说句大实话
AI幻觉这个问题,本质上反映了整个行业的一个误区:我们太追求"看起来很厉害",而忽略了"实际上很可靠"。OpenAI这篇论文最有价值的地方,可能不是提出了什么新技术,而是提醒整个行业:有时候慢即是快,少即是多。
反正我现在用AI写代码时,都会多一个心眼——特别是涉及到API调用和技术细节时,一定会去官方文档核实一下。毕竟,AI说"这绝对是对的",和我说"我觉得这是对的",可信度可能差不太多。
希望未来的AI能更像个谦逊的专家,而不是自信的骗子。毕竟,在这个信息爆炸的时代,知道自己不知道,可能比知道答案更重要。


