Meta这次可能真的"黄"了。不是股价下跌那种黄,是字面意义上的——被两家成人电影公司告上法庭,索赔3.59亿美元,原因是涉嫌偷偷下载2396部成人电影训练AI。这事听起来像段子,但法律文件堆起来能让你明白:AI行业的"数据原罪",终于藏不住了。

一、2396部电影,3.59亿美元:Meta的"成人内容采购计划"
2025年7月23日,美国加州北区联邦法院收到一份特别的起诉状:原告是Strike 3 Holdings和Counterlife Media两家成人电影公司,被告栏赫然写着"Meta Platforms, Inc."。这不是普通的版权纠纷,原告指控Meta从2018年开始系统性地通过BT网络下载他们的成人电影,用于训练包括视频生成器Meta Movie Gen、LLaMA大语言模型在内的AI产品。
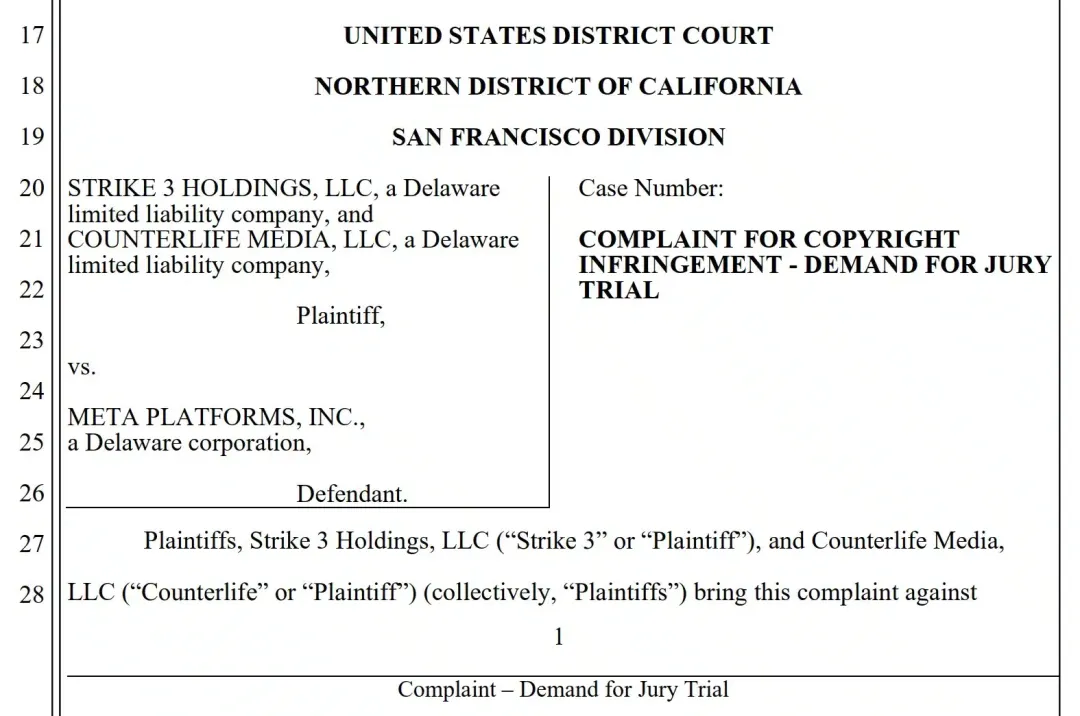
最扎眼的是赔偿金额:根据美国版权法,法定赔偿上限是每部作品15万美元。2396部电影乘以15万,正好是3.594亿美元。这个数字足够Meta买20万个8TB硬盘,或者给每个员工发1.5个月奖金——但他们偏偏选择了"免费下载"这条路。

二、从影子图书馆到家庭Wi-Fi:Meta的"数据采集全链路"
这事要从2023年Meta的另一场官司说起。当时一批作家起诉Meta用盗版图书训练LLaMA模型,Meta在庭审中不小心说漏嘴:他们确实通过BitTorrent从"影子图书馆"(也就是盗版资源库)下载了81.7TB数据。更实诚的是,他们还承认设置了6个虚拟私有云服务器,用匿名IP掩盖BT下载行为,甚至写了专门脚本控制做种——生怕别人不知道他们在"偷数据"。

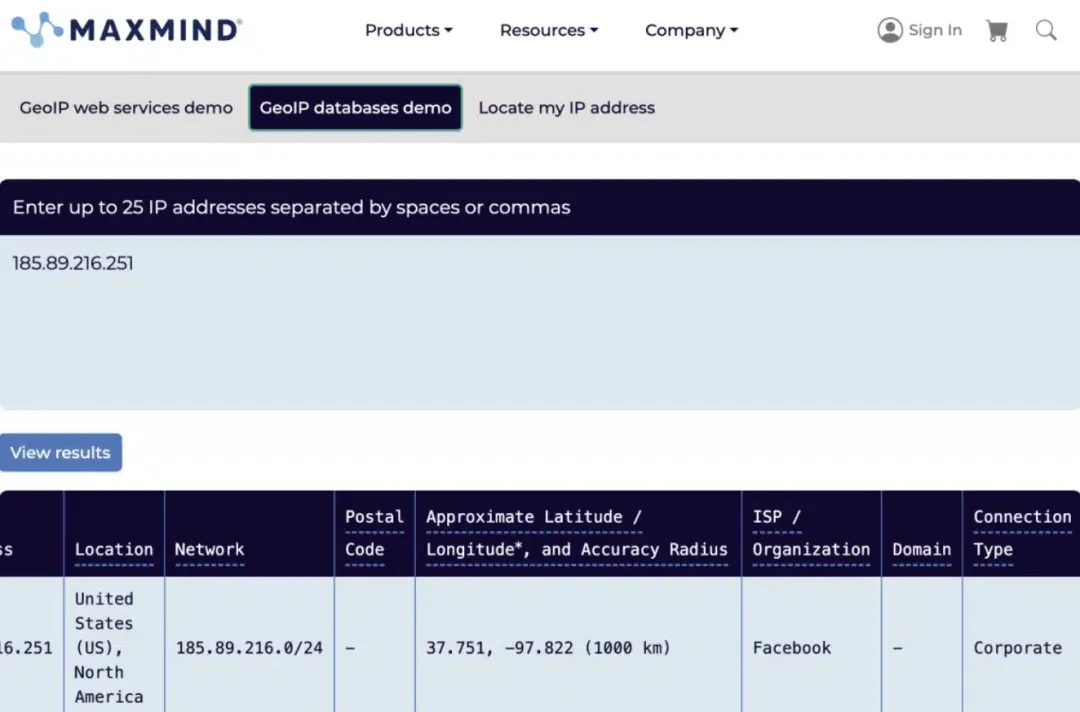
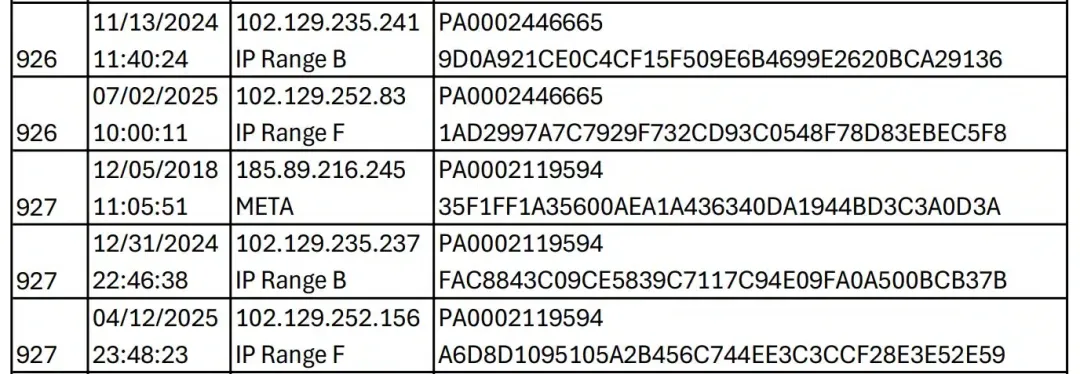
Strike 3的律师顺着这条线索一查,发现了更精彩的:他们用自家开发的VXN Scan和Cross Reference工具,追踪到47个Facebook所属IP地址在持续下载成人电影。这些IP不是偶尔为之,而是从2018年到2025年,七年如一日地"追剧"。

最绝的是IP追踪结果。比如185.89.216.251这个地址,MaxMind数据库直接标注归属Facebook,连接类型是企业网络。更魔幻的是,有个IP追到了Comcast家庭宽带,绑定在某个Facebook员工家里——看来是公司服务器下不完,回家接着用自家Wi-Fi干"兼职"。
这些IP的下载记录堪称"专业级":高频、长时段、多分辨率同步下载,行为模式高度一致。Strike 3的技术团队判断,这明显是机器脚本在操作,不是人类用户行为。
三、为什么AI偏偏"爱看"成人电影?
你可能觉得奇怪,Meta这么大公司,要啥数据没有,为啥非要盯着成人电影?Strike 3的起诉状里倒是说得挺实在——他们的片子对AI训练来说,简直是"五星级食材"。

说白了就是:成人电影画质高(很多是4K)、镜头稳定(不会像电影那样频繁切换)、表情自然(毕竟是"沉浸式表演")、动作连贯(场景变化少)、对话有节奏(虽然内容单一但发音清晰)。这些特点对训练视频生成AI来说,简直是量身定制。
对比一下:电视剧镜头切换太快,新闻视频没有人物互动,YouTube视频画质参差不齐,成人电影却完美符合AI训练的"稳定性需求"。更别提那些"独特场景"——其他类型视频根本提供不了。
BT网络的特性也帮了Meta大忙。BT下载讲究"tit for tat"(以牙还牙),你分享给别人越多,自己下载速度就越快。Meta的操作堪称"聪明":把下载的片子做种分享,用别人的资源换回更多下载带宽。这已经不是简单的"偷",而是主动的"数据交易"了。
四、撞上"版权维权专业户":Strike 3的"钓鱼执法"生意经
这次Meta算是踢到铁板了。Strike 3可不是普通的小公司,他们是成人内容行业的"维权专业户"。数据显示,2017到2023年间,这家公司在联邦法院提起了9508起版权诉讼,光2022年在加州北区就告了200多起。

他们的商业模式堪称"版权钓鱼":用VXN Scan系统24小时监控BT网络,抓那些下载他们影片的IP地址,然后发律师函索赔。普通人收到这种信,大多愿意花几百美元私了——毕竟谁也不想因为"看片"上法庭。

但这次他们盯上的是Meta——市值1.7万亿美元的科技巨头。这就像小渔船撒网捞到了鲸鱼,双方的法律资源根本不是一个量级。不过Strike 3有个优势:他们的证据链太完整了,从IP地址到下载记录,从时间戳到内容比对,简直是给Meta量身定做的"犯罪证据包"。
五、AI行业的"数据脏秘密":你看到的进步,可能藏着别人的隐私
说实话,Meta这事儿不算新鲜,只是这次"口味"比较特别。整个AI行业都在回避一个核心问题:训练数据到底哪来的?没人说得清,也没人愿意说清。
你以为AI模型吃的是干净数据?可能是你的医疗影像、你家的监控录像、你写的小说、甚至你和朋友的聊天记录。这些数据在黑夜里被悄悄爬取、清洗、喂给AI,最后变成"技术进步"的成果展示给你看。
就像Meta Movie Gen这个模型,说不定哪天就能一键生成"以假乱真"的视频,演员表情比真人还自然——但你永远不知道它是看了多少"教学视频"才学会的这些动作。
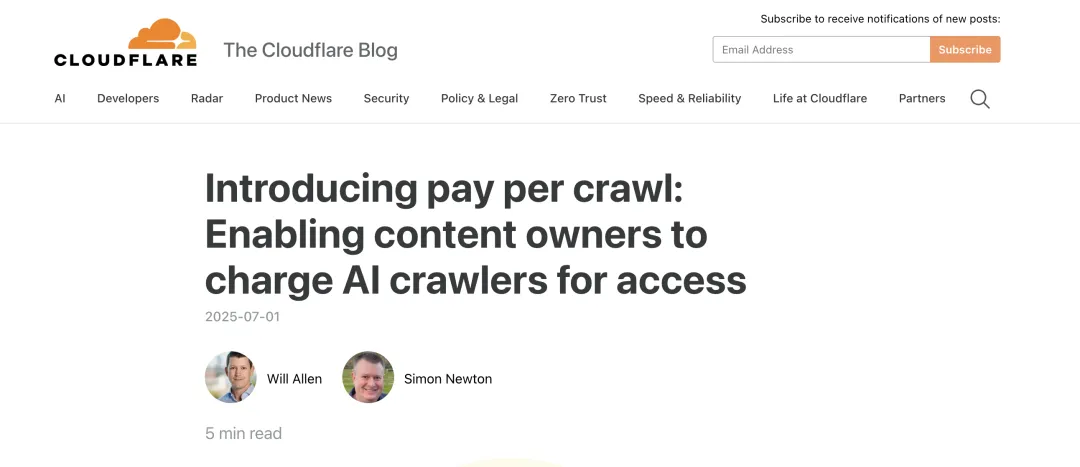
不过也不是所有人都在装睡。上个月Cloudflare就更新了政策:默认拦截所有未经许可的AI爬虫。他们的博客标题说得很直接:《按抓取付费:让内容所有者向AI爬虫收取访问费用》。意思很明确:想拿数据?先问过主人,最好付费。
这才是健康的行业生态吧?训练AI之前先考虑别人的权利,而不是先上车后补票,被抓了再想怎么公关。
Meta到现在还没回应这场官司。估计要么在准备天价和解金,要么在找技术漏洞洗白自己。但不管结果如何,有个事实不会变:AI吃进去的数据,最终会以某种形式吐出来影响世界。而那些被悄悄吃掉的"素材",可能就包括你我生活的片段。
下次再看到AI生成的完美视频,你可能会忍不住想:这表情,这动作,它到底是跟谁学的?


