Meta FAIR团队刚刚扔出一颗重磅炸弹——Code World Model(CWM),一个320亿参数、支持131k上下文的密集型语言模型,专为代码生成和推理而生。更关键的是,它不是又一个“会写代码的LLM”,而是首个系统性引入“世界模型”概念的代码大模型。
简单说:CWM不仅能写代码,还能“脑内模拟”这段代码跑起来时变量怎么变、函数怎么调、哪里会崩——就像程序员用pdb单步调试那样。
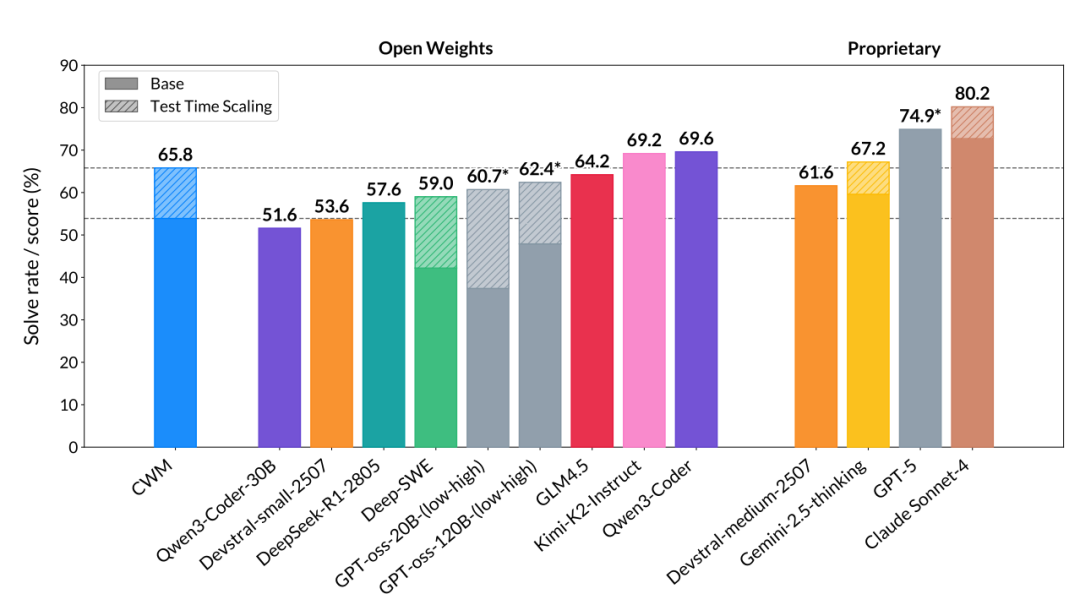
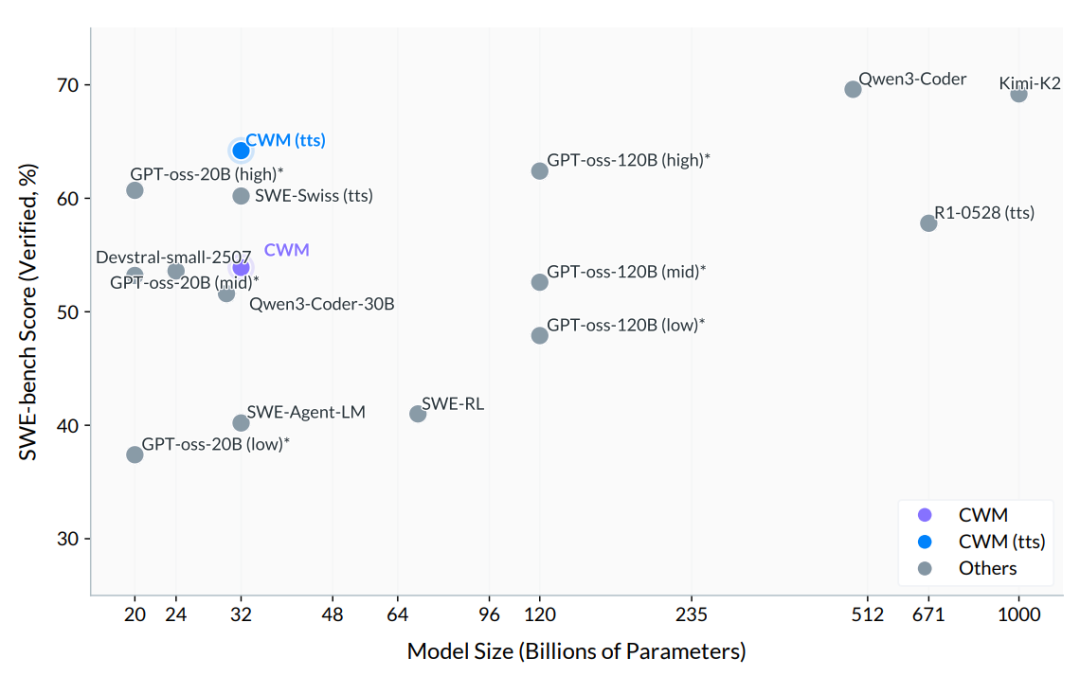
这事儿有多重要?看数据就知道:在权威代码评测SWE-bench Verified上,CWM拿下65.8分,碾压所有开源同规模模型,直逼GPT-4水平。
连Yann LeCun本人都亲自转发了项目发布消息,还顺手回怼了一个质疑者:“这是编码,不是ASI(人工通用智能)。”
为什么现有代码模型“写得对但跑不通”?
当前主流代码大模型(比如CodeLlama、DeepSeek-Coder)本质上还是“文本预测器”。它们把代码当成一串字符序列,靠统计规律猜下一个token是什么。结果就是:生成的代码语法正确、结构漂亮,但一跑就错——变量未定义、边界条件漏判、副作用没考虑。
问题出在哪?它们不懂“执行”。
CWM团队一针见血:如果模型连“变量x在第5行被赋值为3”这种动态状态变化都不知道,怎么可能写出可靠代码?
于是,他们干了件狠事:让模型直接学习“代码执行轨迹”。
比如下面这个统计"strawberry"中’r’个数的函数,CWM不仅能生成代码,还能一步步追踪执行状态:
- 初始:
count = 0 - 第一次循环:
char = 's'→count不变 - 第二次循环:
char = 't'→count不变 - ……
- 第六次循环:
char = 'r'→count = 1 - ……
- 最终返回
count = 3

这种能力让CWM实现了三大突破:
1. 代码执行模拟:提前预判哪里会崩
CWM能在生成代码的同时,模拟执行路径,预判空指针、越界访问、死循环等常见错误。相当于内置了一个“神经调试器”。
2. 自我修复:写错自动改,改完自动测
它能自动生成测试用例,发现失败后尝试多种修复策略——写→测→改→再测,形成完整开发闭环。
3. 推理规划:复杂问题拆解成可执行步骤
面对编程竞赛题或数学问题,CWM会先规划函数结构、变量设计,再结合执行预测逐步生成验证,展现出类人的多步推理能力。
技术底牌:32B参数 + 三阶段训练
CWM不是凭空冒出来的。它的架构和训练流程都经过精心设计。
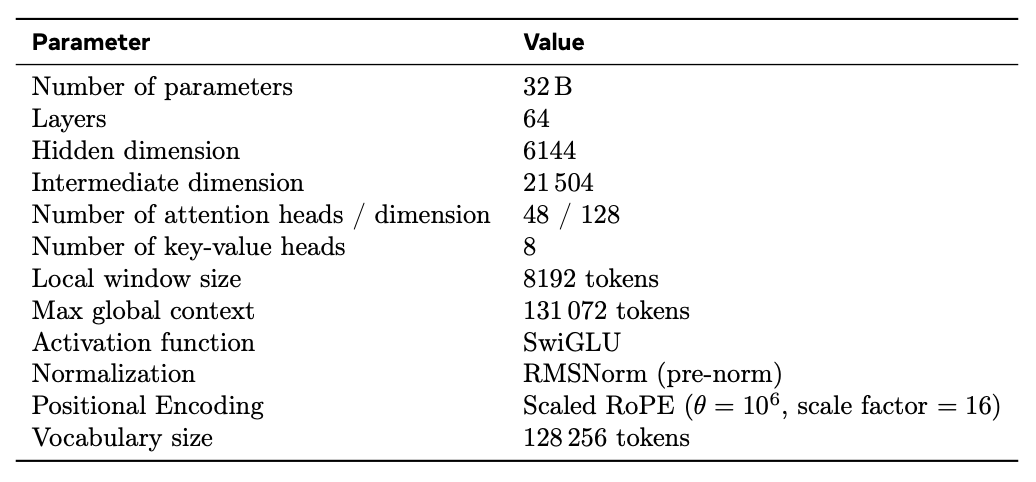
模型参数:32B密集模型,64层Transformer,使用SwiGLU激活函数,支持131k上下文——足够塞进整个中型项目的代码库。
训练分三步走:
- 预训练:8T tokens通用语料(30%为代码),上下文8k,打好基础。
- 中期训练(关键!):5T tokens的“世界建模”数据,包括:
- 数千万Python函数的执行轨迹(变量状态变化记录)
- 300万条智能体在Docker中真实修复Bug的交互日志
- 执行过程的自然语言描述(便于泛化)
- 后训练:100B tokens监督微调 + 172B tokens多任务强化学习,覆盖SWE-bench、编程竞赛、数学题等真实任务。
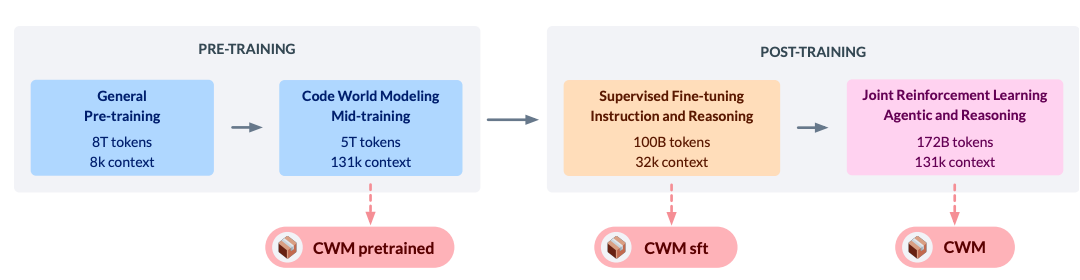
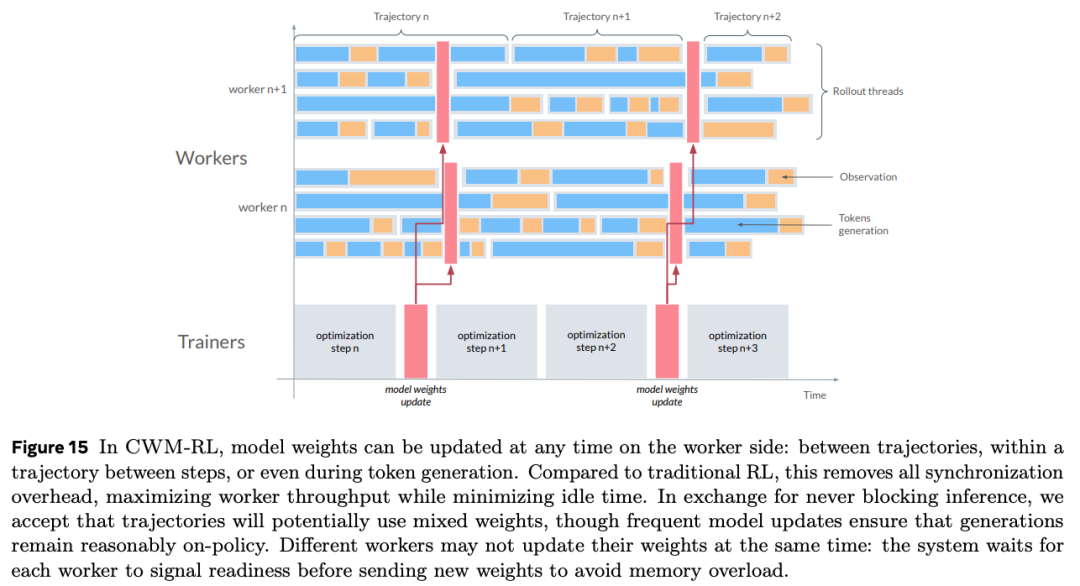
特别值得注意的是强化学习阶段——Meta用了异步RL架构,多个“Worker”并行生成代码并执行反馈,Trainer实时更新模型,效率拉满。
性能实测:不只是理论漂亮
CWM在多个硬核评测中表现亮眼:
- SWE-bench Verified:65.8%(开源模型第一)
- LiveCodeBench v5:68.6%(高复杂度任务)
- Math-500:96.6%
- Terminal-Bench:26.3%(超过Gemini 2.5 Pro)
从模型规模与性能的关系看,CWM(紫色点)明显优于同体量模型,甚至逼近更大参数的闭源模型。
不过也得说清楚:目前CWM只支持Python。C++、Java等语言的世界建模还没做,符号执行、内存安全分析这些更复杂的场景也还没覆盖。
开源诚意足,但别指望拿来当聊天机器人
Meta这次开源相当大方:模型权重、训练代码、各阶段checkpoint全部放出,连训练细节都写得明明白白。
但有两个重要限制:
- CWM没做RLHF,不适合对话——你别指望拿它当Copilot聊天。
- 仅限非商业研究使用——想商用?先找Meta谈授权。
项目核心成员Gabriel Synnaeve在推文中难掩兴奋:“为CodeGen团队骄傲!博士生和资深工程师一起拼,Meta领导层全力支持。”
世界模型,是代码AI的下一个拐点吗?
CWM的出现,其实是在回答一个根本问题:大模型要怎样才能真正理解代码?
过去我们靠堆数据、扩参数,让模型“见过”足够多的代码模式。但CWM走的是另一条路:教模型理解代码的“物理规律”——执行时的状态变迁。
这有点像从“背菜谱”升级到“懂火候”。你背一万道菜谱,不如亲手炒过一百次知道油温几成、什么时候该翻锅。
当然,现在说CWM能取代程序员还太早。但它确实证明了一件事:让AI理解“世界如何运作”,比让它记住“世界长什么样”更重要。
Meta没开源二维码、没搞扫码入群、没推付费课程——就安安静静扔出一个技术突破,然后问了句:“如果大模型能理解世界,它能成为更好的程序员吗?”
我觉得,这个问题,值得每个写代码的人想想。


