作为一个每天都在跟各种AI模型打交道的科技爱好者,最近试了不少新出的大模型,发现一个挺有意思的现象:很多厂商还在拼参数规模,动不动就"万亿参数"起步,但实际用起来却未必顺手。直到我上手体验了智谱刚发布的GLM-4.5,才算明白什么叫"参数不在多,够用则灵"。
先看核心数据:全球第三的综合实力
衡量一个大模型到底行不行,还是得看硬数据。GLM-4.5在12个主流评测基准上的综合得分为63.2分,这个成绩在全球所有模型里排第三,在国产模型和开源模型里都是第一。有意思的是,它的总参数量是3550亿(激活参数320亿),比DeepSeek-R1少一半,比Kimi-K2更是只有三分之一,但性能反而更优。
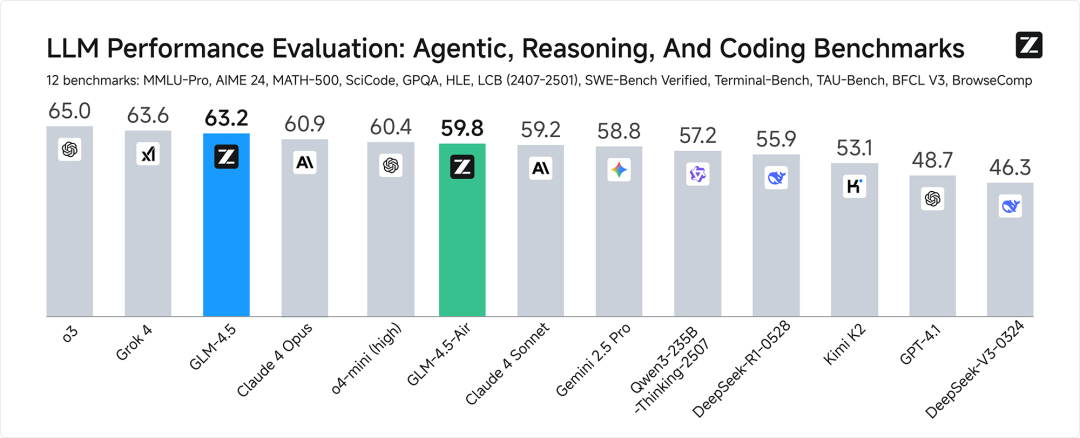
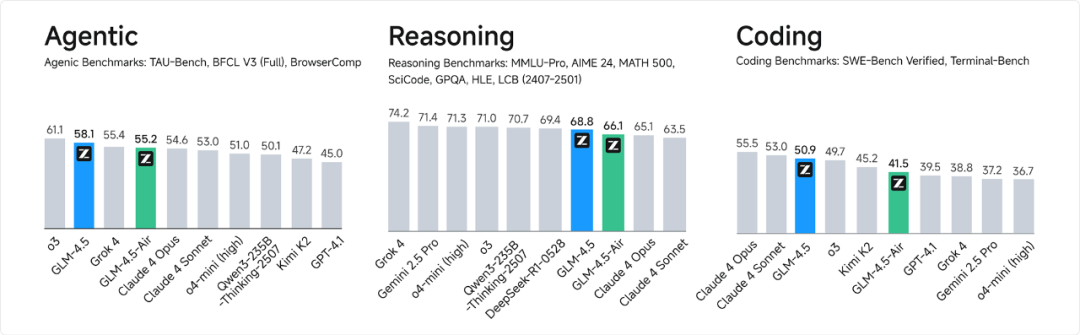
拆开来看专项能力更能说明问题。在Agentic(智能体)、Reasoning(推理)和Coding(代码)这三个关键维度,GLM-4.5表现都很均衡,没有明显短板。现在做AI应用开发,最怕模型"偏科"——要么只会写代码不会推理,要么推理强但工具调用一塌糊涂,而GLM-4.5这种全面发展的特性,其实更符合实际开发需求。
参数效率才是真本事:小身材大能量
我一直觉得,衡量大模型技术水平的关键指标不是"参数总量",而是"参数效率"——用多少参数实现了多少性能。GLM-4.5在这方面确实让人眼前一亮。在SWE-bench代码能力评测里,它的性能/参数比直接跑到了帕累托前沿,简单说就是:相同参数规模下它性能最好,相同性能下它参数最少。
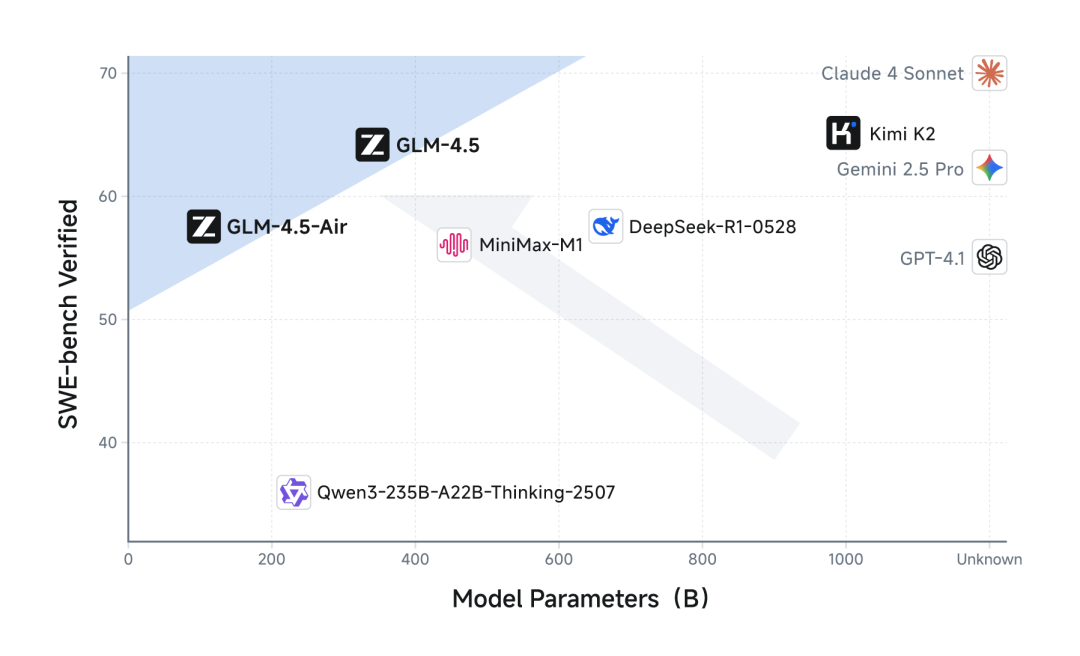
为什么能做到这一点?看训练数据就知道,它先是在15万亿token的通用数据上打底,又针对性用了8万亿token的代码、推理、智能体数据做微调,最后还用强化学习优化。这种"广撒网+精耕细作"的训练策略,比单纯堆参数要聪明得多。
速度和成本:开发者最关心的两个硬指标
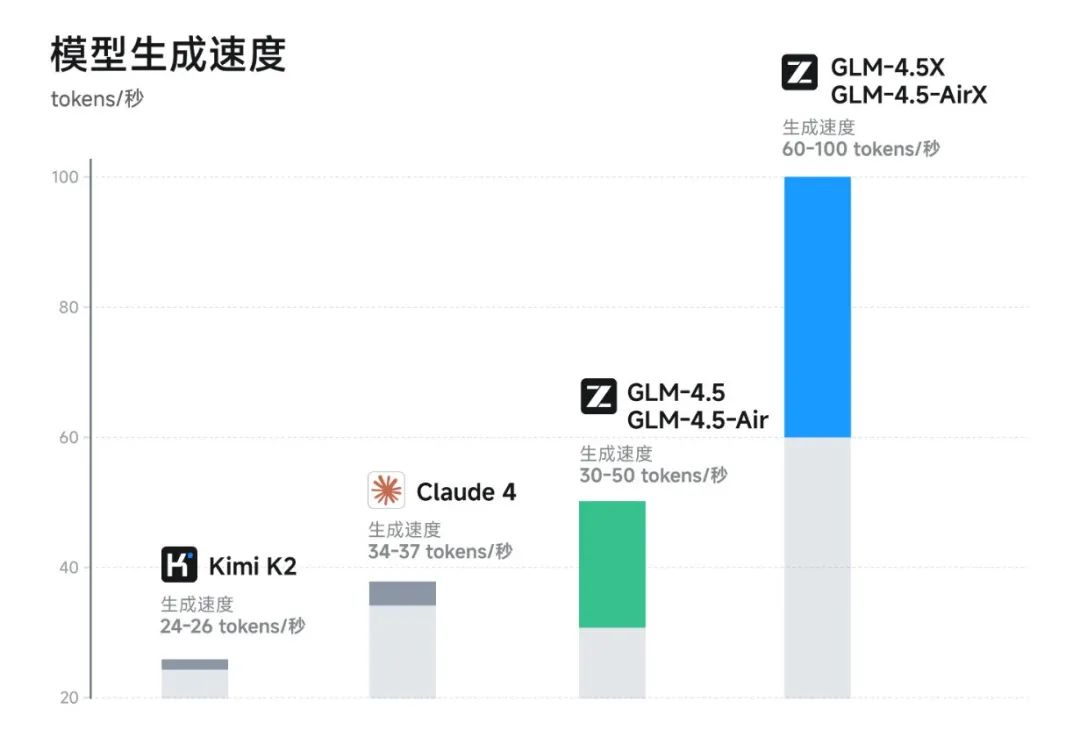
对开发者来说,性能再好,跑不快、用不起也是白搭。GLM-4.5这次在速度上确实下了功夫,高速版能跑到100 tokens/秒,什么概念?相当于你刚打完一段话,模型已经生成了两三百字的回复,这种交互体验跟卡顿的模型完全不是一个级别。
成本方面更有惊喜。API价格输入只要0.8元/百万tokens,输出2元/百万tokens,对比一下同类模型,这个价格几乎是地板价了。特别是GLM-4.5-Air这个轻量版,参数规模小一些,但价格更低,对中小开发者和测试场景太友好了。
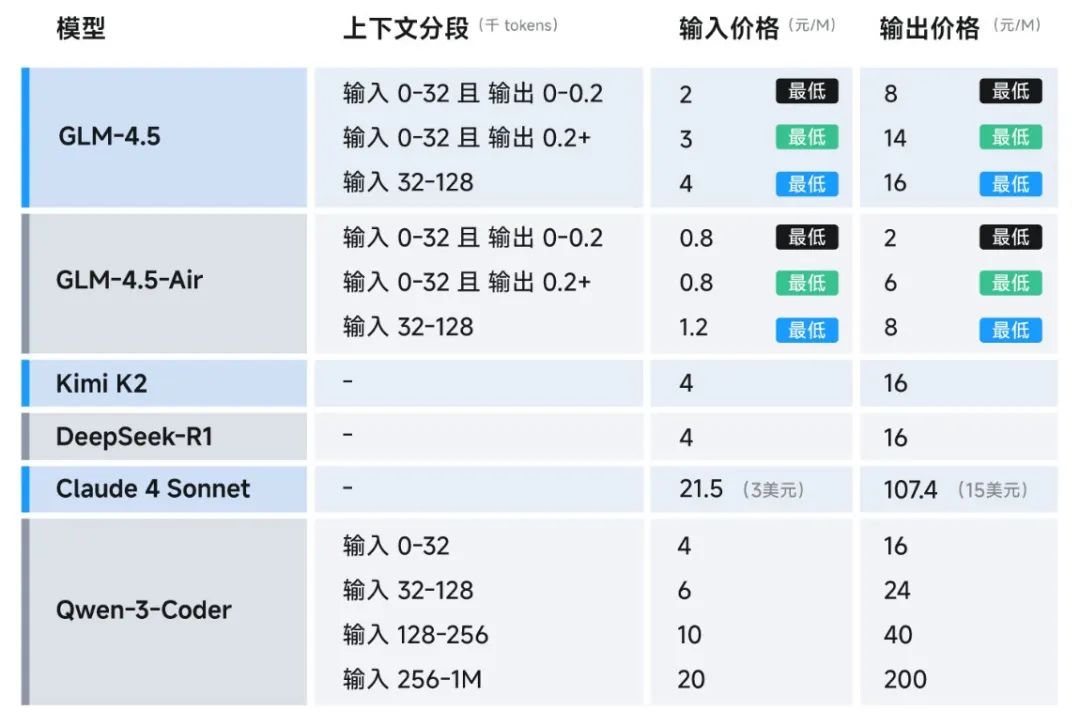
真实开发场景:代码智能体能力实测
跑分好看是一回事,实际干活怎么样才重要。官方做了个挺有意思的测试:在52个真实开发任务里,让GLM-4.5跟Qwen3-Coder、Kimi-K2这些热门模型正面刚,结果GLM-4.5对Qwen3-Coder的胜率达到80.8%,在工具调用可靠性和任务完成度上优势明显。
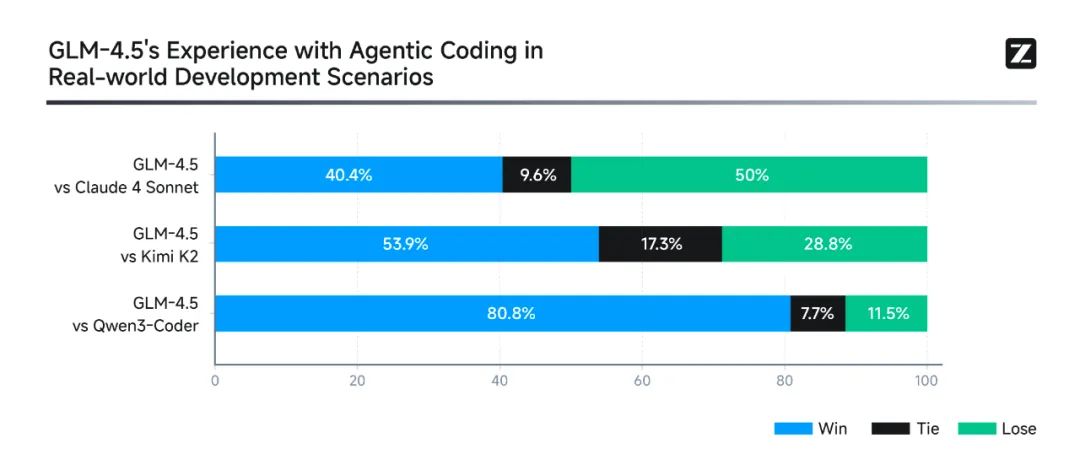
我自己试了让它从零写个简单的搜索引擎,没想到它不仅生成了前端界面,还自动对接了搜索接口,输入关键词真的能返回结果。这种从"理解需求"到"实现功能"的端到端能力,比那些需要人类一步步拆解任务的模型强太多了。
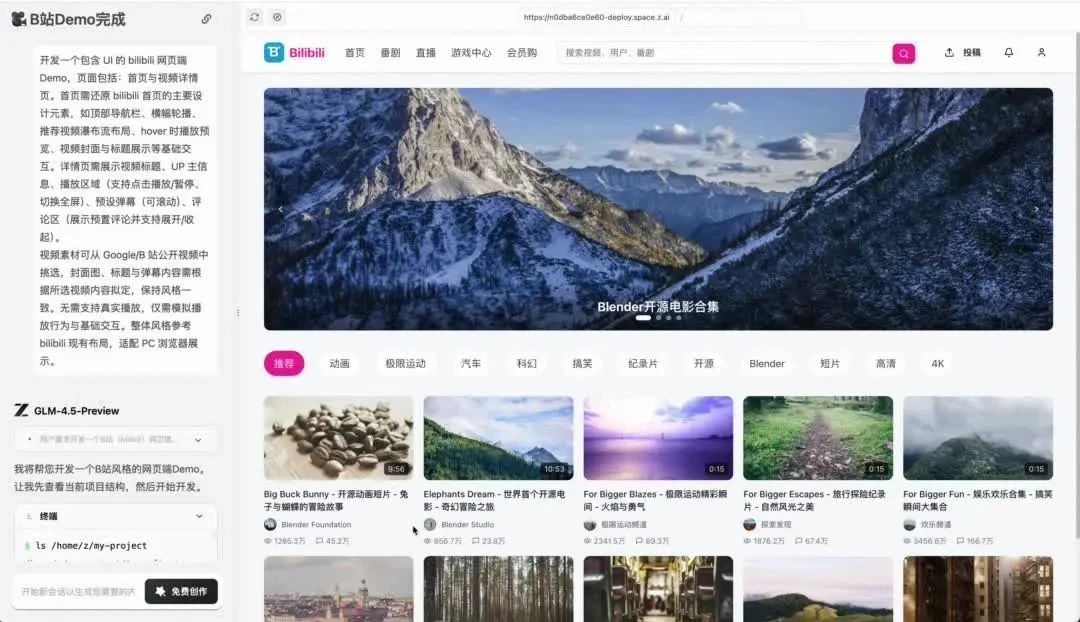
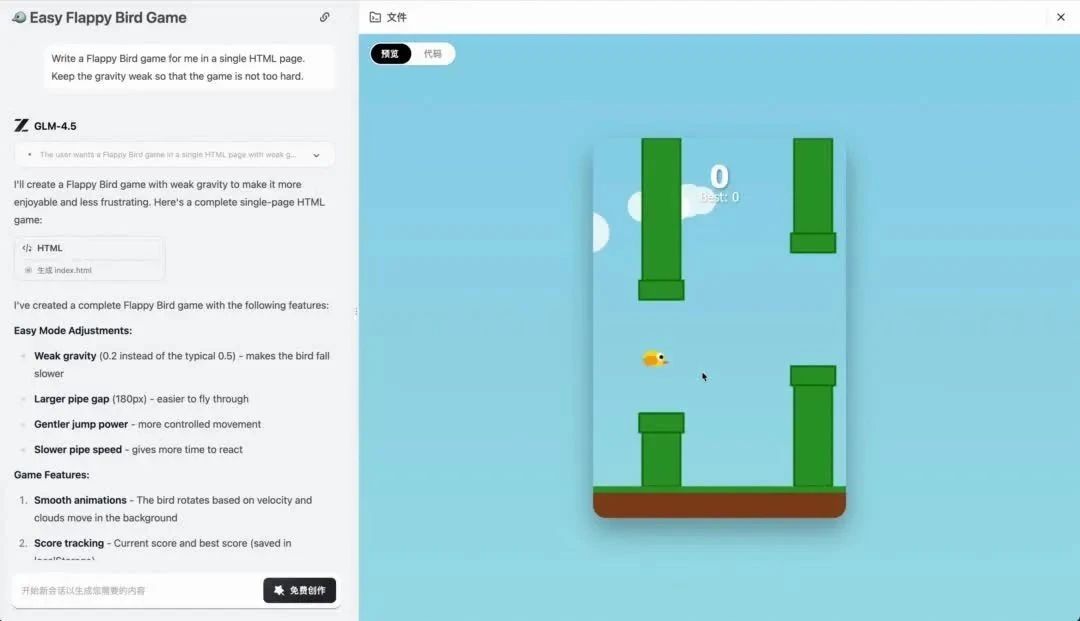
类似的还有B站风格的视频网站Demo,不仅能播放视频,还支持发弹幕、切换清晰度,交互逻辑完全闭环。最惊讶的是Flappy Bird游戏,从物理引擎到碰撞检测再到计分系统,一个AI模型从零开始独立完成,这放在半年前简直不敢想。
一点思考:大模型的"性价比"时代来了?
体验下来,GLM-4.5最让我感慨的不是"国产第一"这个头衔,而是它展现出的技术路线——不再盲目追求参数规模,而是在效率、速度、成本上下功夫。这种思路其实更符合AI技术落地的实际需求:企业需要能用得起的模型,开发者需要能快速迭代的工具,用户需要流畅的交互体验。
当然,它也不是完美的,比如跟Claude-4-Sonnet比还有提升空间,但作为开源模型,能做到这个水平已经超出预期。现在模型权重已经在Hugging Face和ModelScope开放,MIT许可证意味着商用也没问题,感兴趣的开发者真的可以上手试试。
最后想说,衡量一个AI模型的价值,从来不是看它发布会多热闹,而是看它能不能实实在在解决问题。GLM-4.5这次用数据证明:好的大模型,应该是聪明的(性能强)、高效的(参数省)、快速的(响应快)、便宜的(成本低)——这或许就是下一代大模型的核心竞争力。


