一、什么是向量
随着ChatGPT的爆火,其embedding背后的向量检索技术让大家熟知。事实上,向量数据库并非近两年才出现的新技术,它已经存在了很长时间了。要了解什么是向量数据库,我们先来了解下什么是向量。
向量的概念
向量最初是数学和物理学中的一个基本概念,他表示既有大小又有方向的量,它与只有大小没有方向的标量(如温度、质量和长度)相对应。
在数学中,向量(也称为欧几里得向量、几何向量、矢量),指具有大小(magnitude)和方向的量。它可以形象化地表示为带箭头的线段。箭头所指:代表向量的方向;线段长度:代表向量的大小。与向量对应的只有大小,没有方向的量叫做数量(物理学中称标量)。 如果用Rn表示n个实数的有序集,Rn中的一个向量就是一个n元有序组, 向量的记法:印刷体记作粗体的字母(如a、b、u、v),书写时在字母顶上加一小箭头“→”。如果给定向量的起点(A)和终点(B),可将向量记作
。实际上向量有多种记法,可以用元组表示一个向量,如 (x1, x2) 或 < x1, x2>。在线性代数中,n元向量可以用n×1矩阵表示,如:
向量中的每个元素xn,都称作向量的一个分量。
向量的特点
- 方向和大小:向量不仅有大小,还有方向,这与普通的数(标量)不同,标量只有大小,没有方向。
- 可在空间中表示:向量可以在一维、二维、三维或更高维的空间中表示。
- 可相加减和数乘:向量之间可以进行加法、减法操作,也可以与标量进行乘法操作,遵循平行四边形法则和三角形法则。
- 向量空间:向量可以构成向量空间,向量空间内的向量可以通过向量加法和标量乘法的组合进行线性组合。
数的向量化表示对计算机运算的便利性
- 高效存储和处理:计算机通过向量化表示可以更高效地存储和处理大量数据。向量化可以减少循环和迭代计算,利用现代处理器的向量化指令集进行并行处理。
- 简化计算:数学运算,尤其是线性代数运算,在向量化表示下可以大大简化,因为可以利用矩阵乘法等操作直接处理整个数据集合,而不是单独处理每个数据点。
- 机器学习和深度学习:在机器学习和深度学习中,数据通常以向量、矩阵和张量的形式表示。向量化使得算法的实现更加直观,同时可以利用高度优化的数学库(如NumPy、TensorFlow、PyTorch)进行高效计算。
- 图形处理:在计算机图形处理中,向量化表示允许快速计算和渲染图形,比如在3D建模、动画和视频游戏开发中的应用。
机器学习中为什么使用向量
在计算机世界中,向量的使用普遍且多样,特别是在机器学习中,向量用来描述特征有其独到之处和优势:
1. 数据表示的统一性和通用性
- 统一性:使用向量来描述特征可以将不同类型的数据(数值、类别、文本等)转化为统一的数学表示形式。这种统一性使得算法能够处理多种类型的数据,而不需要根据数据类型改变算法逻辑。
- 通用性:向量化的数据可以被各种机器学习算法接受,从简单的线性回归到复杂的深度学习模型,都可以处理向量形式的输入数据。
2. 高效的计算和存储
- 高效计算:现代计算机和特定硬件(如GPU)对于向量和矩阵运算进行了优化,使得与向量相关的计算特别高效。这意味着使用向量来描述特征可以显著加快机器学习算法的训练和预测过程。
- 高效存储:向量化的数据可以通过紧凑的格式存储,减少内存占用,并且便于数据的快速读取和传输。
3. 算法性能的提升
- 特征工程:通过将特征向量化,数据科学家可以应用各种特征工程技术(如特征选择、特征提取、维度缩减)来提升模型性能。
- 模型精度:向量化的特征表示允许模型捕捉到数据中的复杂模式和关系,从而提高模型的精度和泛化能力。
4. 灵活性和扩展性
- 灵活性:向量表示的特征可以容易地扩展或修改,以适应模型的需要。例如,可以通过添加更多的维度来引入新的特征,而不需要对现有的数据处理流程或模型架构进行大的改动。
- 扩展性:对于大规模的数据集,向量化的表示方法可以有效地支持并行计算和分布式计算,从而使得处理大数据变得可行。
5. 兼容性与集成性
- 软件库和工具:几乎所有的机器学习和深度学习库(如scikit-learn、TensorFlow、PyTorch)都是围绕向量和矩阵运算设计的。使用向量来描述特征使得这些工具可以直接应用,无需进行数据格式转换。
- 集成性:向量化的特征可以方便地与其他数据处理和分析工具集成,如数据可视化、统计分析等,为整个数据处理和机器学习流程提供支持。
举例
例如电影推荐系统中
假设我们正在构建一个电影推荐系统,我们希望根据用户的历史观影记录和电影的属性来推荐用户可能感兴趣的电影。
让我们细化一下电影推荐系统中电影特征向量化和用户特征向量化的过程,以便更深入理解这一概念。
电影特征向量化的细化
假设我们有以下电影特征进行向量化:
-
数值特征:
- 电影长度(分钟):一个直接的数值,比如
120。 - 发布年份:一个数值,比如
2020。
- 电影长度(分钟):一个直接的数值,比如
-
类别特征(电影类型):
- 假设我们有5种类型:动作、喜剧、科幻、爱情、惊悚。
- 电影《X》是动作和科幻类型,所以它的类型特征向量可以是
[1, 0, 1, 0, 0],表示动作和科幻为1,其他为0。
-
文本特征(电影描述):
- 电影《X》的描述:“一个未来的英雄战斗以拯救世界。”
- 使用TF-IDF或词嵌入技术将这段文本转换为固定长度的向量,例如,一个长度为
N的向量[0.5, 0.1, ..., 0.0],每个元素代表文本中一个特定词或概念的重要性。
用户特征向量化的细化
对于用户,我们可能会有如下特征进行向量化:
-
用户偏好:
- 假设基于用户过去的评分记录,我们得出用户喜欢动作和科幻类型的电影。
- 用户的偏好向量可能类似于电影的类型向量,如
[0.8, 0.2, 0.7, 0.1, 0.0],表示用户偏好动作和科幻类型的电影,数值越高表示偏好程度越大。
-
评分活动:
- 用户评分次数:一个数值,比如
50次。 - 平均评分:另一个数值,比如
4.2。
- 用户评分次数:一个数值,比如
-
观影频率:
- 根据用户的观影记录,我们可以计算出用户每月的观影频率,比如
8部电影/月,这也可以转化为一个数值特征。
- 根据用户的观影记录,我们可以计算出用户每月的观影频率,比如
综合向量表示
- 电影向量:将数值特征、类别特征和文本特征的向量合并,形成一个综合的电影特征向量。例如,如果我们将所有特征合并,对于电影《X》,它的特征向量可能是
[120, 2020, 1, 0, 1, 0, 0, 0.5, 0.1, ..., 0.0],前面部分代表数值和类别特征,后面部分是文本特征转化来的向量。 - 用户向量:同样地,将用户的偏好、评分活动和观影频率合并成一个综合的用户特征向量,例如
[0.8, 0.2, 0.7, 0.1, 0.0, 50, 4.2, 8]。
综合特征向量化后,我们可以通过计算向量之间的相似度来找到电影与用户偏好之间的相关性。这是机器学习和推荐系统中的一个常见步骤,它帮助我们理解和量化项目(如电影)与用户之间的匹配程度。以下是几种常用的相似度计算方法:
1. 余弦相似度(CONSINE)
余弦相似度是衡量两个向量在方向上的相似度,忽略它们的大小。它的值范围从-1(完全相反)到1(完全相同),0表示两个向量之间没有相关性。即计算向量空间中两个点的夹角大小,夹角越小,相似度越高,公式如下:
其中, 和 是两个向量, 是向量的点积, 和 是向量的欧几里得范数(即向量的长度)。
2. 欧几里得距离(欧氏距离)(L2)
欧几里得距离(或称欧式距离)测量的是两个向量在多维空间中的“直线”距离。距离越小,相似度越高。公式如下:
其中,和 是向量 和 在第 个维度上的值。
3. 内积(IP)
两个嵌入之间的IP距离定义如下:
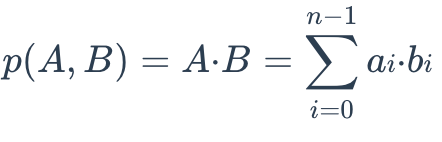
如果您需要比较非标准化数据或当您关心幅度和角度时,IP 会更有用。如果您使用 IP 来计算嵌入相似度,则必须对嵌入进行标准化。归一化后,内积等于余弦相似度。
假设 X’ 通过嵌入 X 进行归一化:
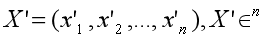
两个embedding之间的相关性如下:
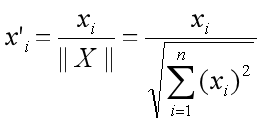
4. 曼哈顿距离
曼哈顿距离(或城市街区距离)测量的是在标准坐标系统中从一个点到另一个点的距离,只沿着坐标轴方向计算。公式如下:
这种方法在某些情况下比欧几里得距离更有意义,尤其是在维度非常高时。
应用示例
假设我们有一个用户的特征向量 和两部电影的特征向量 和 。我们可以使用上述任何一种方法来计算用户向量与每部电影向量之间的相似度。
- 如果我们使用余弦相似度,我们可能会发现 和 之间的相似度为 0.9(非常相似),而 和 之间的相似度为 0.3(不太相似)。基于这些结果,推荐系统会倾向于推荐 给用户。
这个计算过程不仅适用于个性化推荐,还可用于聚类分析(将相似的电影或用户分为组)、异常检测(识别与大多数用户或项目显著不同的情况)等任务。
通过这种方式,机器学习模型可以根据综合特征向量的相似度,有效地识别并推荐用户可能感兴趣的电影,实现个性化推荐。
二、向量数据库
目前市场上存在许多向量数据库产品。从国内和国外两个维度来看,国内有
- Milvus
- 京东的VEARCH
- 蚂蚁金服的ZSearch等产品。
Milvus是目前向量数据库赛道里较为热门的产品,而京东和蚂蚁更多的是将它们的应用于内部场景,外部使用较少。
在海外来看,大公司都有自己的向量数据库产品,比较知名的有如Qdrant和Weaviate等等。此外,Pinecone是目前商业向量数据库市场最热门的产品。国内的商业数据库产品有联汇和爱可生自己开发的向量数据库产品,当然这些产品都是基于开源产品进行包装的。
从三个维度来看,这些向量数据库可以分为:向量检索库、向量插件和向量字段。
- 在检索库方面有Meta的Faiss、微软的SPTAG,谷歌的ScaNN等等。
- 插件方面包括ES、OpenSearch和PG等产品中都集成了向量的特性。
- 而向量字段则是数据库本身集成的向量特性,但功能相对较弱。
向量数据库的原理
前面我们介绍到,计算向量空间中两个点的相似度可以使用余弦相似度、欧几里得距离、曼哈顿距离等。一般向量数据库常用的为前两种。
把空间向量两点的值带入公式即可得出一个数值,当两点之间的计算结果符合这个阈值,我们只需要设定一个相似度阈值我们就认为是相似度较高的。
向量索引
当需要检索匹配的数据巨大时,如果将输入的点和巨大的目标集合进行挨个比较计算,这个计算量是无法承受的,因此我们引入了一个概念叫向量索引。
向量索引(vector index):是指通过某种数学模型,对向量构建的一种时间和空间上比较高效的数据结构。借助向量索引,我们能够高效地查询与目标向量相似的若干个向量
说白了就是牺牲一定的准确度来加快检索的效率的一种索引数据结构。
向量索引类型:
-
FLAT (FLAT): 一个基本的线性索引,对数据库中的每个项进行全面扫描,以找到最近的邻居。虽然准确度高,但随着数据量的增加,搜索效率较低。
-
IVF_FLAT (Inverted File with FLAT): 使用倒排文件(IVF)将数据分割成多个桶(或称为聚类),在查询时首先确定查询向量所属的桶,然后在该桶内进行FLAT搜索。这种方法提高了搜索速度,但牺牲了一定的精度。
IVF_FLAT(Inverted File with FLAT)索引是一种用于加速向量搜索的技术,特别适用于高维空间的近似最近邻(ANN)搜索。它结合了倒排索引(Inverted File)和暴力搜索(FLAT)的特点,通过预先聚类减少搜索过程中需要比较的向量数量,从而加速查询过程。其基本原理如下:预处理阶段:
聚类:首先,IVF_FLAT对数据库中的所有向量进行聚类操作,通常使用k-means算法。每个聚类中心(或称为质心)代表了一个向量的聚类。
建立倒排索引:然后,为每个聚类建立一个倒排列表(或称桶),桶中存储属于该聚类中心的所有向量的索引。这样,每个向量就被分配到了一个与之最近的聚类中心对应的桶里。
搜索阶段:当进行向量搜索查询时,IVF_FLAT首先确定查询向量与哪个或哪些聚类中心最接近。
然后,只在与这些最近的聚类中心对应的倒排列表中的向量进行暴力搜索(FLAT),而不是在整个数据库中搜索。
通过这种方式,搜索过程被限制在一小部分相关向量中,显著减少了计算量。 -
IVF_SQ8 (Inverted File with Scalar Quantization): 在IVF的基础上,使用标量量化(SQ8)对向量进行压缩,进一步提高存储和搜索效率,同时牺牲了一定的搜索准确度。
-
IVF_PQ (Inverted File with Product Quantization): 利用产品量化(PQ)技术对向量进行编码和压缩,以减少内存占用并加速搜索。它在保持相对较高搜索质量的同时,大大提高了搜索速度。
-
GPU_IVF_FLAT/GPU_IVF_PQ: 这些是IVF_FLAT和IVF_PQ索引的GPU版本,利用GPU的并行计算能力来加速搜索过程。
-
HNSW (Hierarchical Navigable Small World): 基于小世界网络的一种图索引,提供了高效的近似最近邻搜索,特别是在高维数据集上效果显著。
-
DISKANN (Disk-based Approximate Nearest Neighbor): 一种旨在大规模数据集上运行的索引,优化了磁盘存储和搜索速度,适用于不能完全加载到内存中的大数据集。
-
BIN_FLAT (Binary FLAT): 对二进制向量执行全面扫描的基本索引,类似于浮点数向量的FLAT索引,但专为处理二进制数据设计。
-
BIN_IVF_FLAT (Binary Inverted File with FLAT): 结合了倒排索引和二进制数据的特性,先将数据分割成多个桶,然后在查询时仅在特定的桶内进行搜索,适用于二进制向量数据。
这些索引类型各有优势和适用场景,选择合适的索引类型需要根据具体的应用需求、数据特性和资源限制来决定。例如,对于需要高准确度的应用,可能会选择FLAT或HNSW索引;而对于大规模数据集,可能会选择IVF_PQ或DISKANN以平衡搜索速度和准确度。
向量数据库Milvus使用
Milvus国内比较火,社区比较活跃的一个向量数据库,本地免费使用,他也有Cloud云版本,无需自己运维。
下图是这个Milvus数据库的架构图,这其实是一个经典的分布式系统。
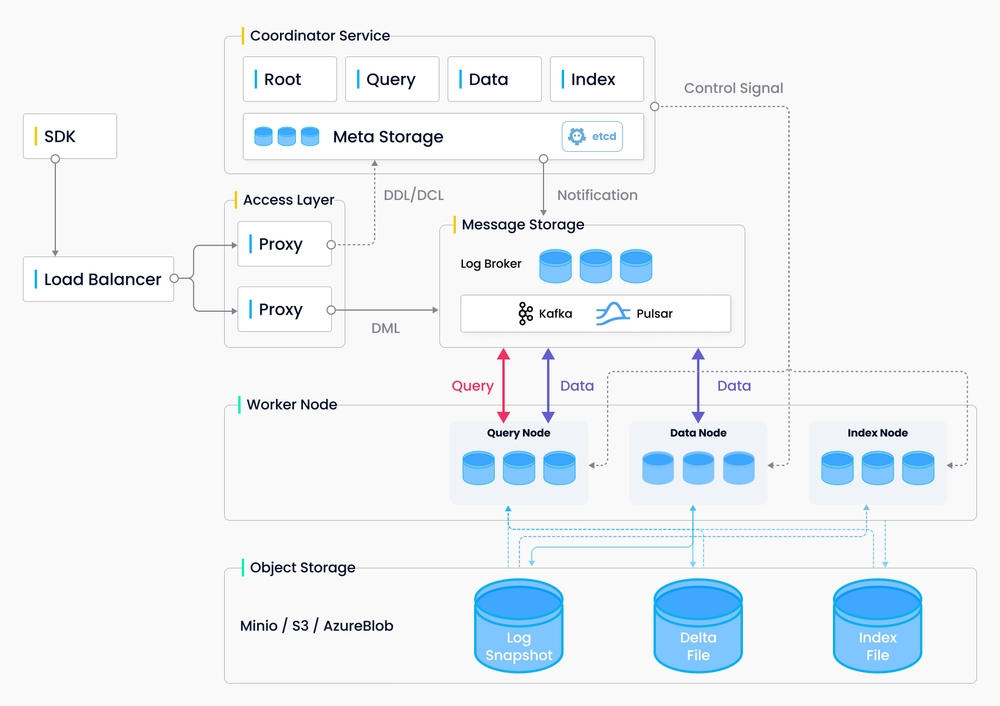
可以看出他最大的特点是存储和计算分离,每一部分都可弹性伸缩切都是无状态的,这是一个典型的分布式系统架构设计。
Milvus的docker安装
Milvus有单机和集群版之分,小规模应用对可靠性没要求的直接使用单机版就够了
新建一个docker-compose.yml内容如下,包含了元数据中心、存储引擎、单机版Milvus以及图形化界面管理工具Attu,其中图形化管理工具是选择性安装的,其他的事必须要有的
version: '3.5'
services:
# 元数据注册中心,用于管理 Milvus 内部组件的元数据访问和存储,例如:proxy、index node 等。
etcd:
container_name: milvus-etcd
# 生产环境用这个
#image: rancher/coreos-etcd:v3.4.16-rancher1
image: quay.io/coreos/etcd:v3.5.0
environment:
- ETCD_AUTO_COMPACTION_MODE=revision
- ETCD_AUTO_COMPACTION_RETENTION=1000
- ETCD_QUOTA_BACKEND_BYTES=4294967296
- ETCD_SNAPSHOT_COUNT=50000
volumes:
- ${DOCKER_VOLUME_DIRECTORY:-.}/volumes/etcd:/etcd
command: etcd -advertise-client-urls=http://127.0.0.1:2379 -listen-client-urls http://0.0.0.0:2379 --data-dir /etcd
# 是存储引擎,负责维护 Milvus 的数据持久化, console界面 http://localhost:9001
minio:
container_name: milvus-minio
image: minio/minio:RELEASE.2022-03-17T06-34-49Z
environment:
MINIO_ACCESS_KEY: minioadmin
MINIO_SECRET_KEY: minioadmin
ports:
- "9001:9001"
volumes:
- ${DOCKER_VOLUME_DIRECTORY:-.}/volumes/minio:/minio_data
command: minio server /minio_data --console-address ":9001"
healthcheck:
test: ["CMD", "curl", "-f", "http://localhost:9000/minio/health/live"]
interval: 30s
timeout: 20s
retries: 3
# 单机版 Milvus
standalone:
container_name: milvus-standalone
image: milvusdb/milvus:v2.2.2
command: ["milvus", "run", "standalone"]
environment:
ETCD_ENDPOINTS: etcd:2379
MINIO_ADDRESS: minio:9000
volumes:
- ${DOCKER_VOLUME_DIRECTORY:-.}/volumes/milvus:/var/lib/milvus
ports:
- "19530:19530"
- "9091:9091"
depends_on:
- "etcd"
- "minio"
# 图形界面管理工具,http://localhost:8000
attu:
container_name: attu
image: zilliz/attu:v2.2.3
environment:
MILVUS_URL: milvus-standalone:19530
ports:
- "8000:3000"
depends_on:
- "standalone"
networks:
default:
name: milvus
直接启动
cd ./milvus
sudo docker-compose up -d
启动成功后看下图形界面是否能够进去
http://localhost:8000
管理 Milvus 连接
from pymilvus import connections
connections.connect(
alias="default",
uri="localhost:19530",
#token="root:Milvus",
user="",
password=""
)
在全局调用一次connect就好了,接下来就可以使用SDK直接操作里面的database、collection
管理Database
默认情况下,让我们不显示创建和指定数据库时,默认使用的就是default
您也可以在 Milvus 中创建数据库,并为某些用户分配权限来管理它们。那么这些用户就有权管理数据库中的集合。一个 Milvus 集群最多支持 64 个数据库。
from pymilvus import connections, db
conn = connections.connect(host="127.0.0.1", port=19530)
database = db.create_database("book")
使用它
db.using_database("book")
您还可以设置连接到 Milvus 集群时使用的数据库,如下所示:
conn = connections.connect(
host="127.0.0.1",
port="19530",
db_name="default"
)
Collection集合管理
from pymilvus import Collection, FieldSchema, CollectionSchema, DataType, connections, utility
connections.connect(alias="default")
schema = CollectionSchema(fields=[
... FieldSchema("int64", DataType.INT64, description="int64", is_primary=True),
... FieldSchema("float_vector", DataType.FLOAT_VECTOR, is_primary=False, dim=128),
... ])
collection = Collection(name="old_collection", schema=schema)
utility.rename_collection("old_collection", "new_collection") # Output: True
utility.drop_collection("new_collection")
utility.has_collection("new_collection") # Output: False
你也可以在不存在时创建集合,并创建向量索引,在存在时加载,代码如下:
def get_milvus_collection(self, collection_name):
# utility.drop_collection(collection_name)
has = utility.has_collection(collection_name)
logger.info(f"Does collection {collection_name} exist in Milvus: {has}")
embeddings_model_dim = EMBEDDING_MODEL_MAPPING[self.embed_model]
# 判断是否存在
if not has:
fields = [
FieldSchema(name="id", dtype=DataType.INT64, is_primary=True, auto_id=True),
FieldSchema(name="doc_id", dtype=DataType.INT64),
FieldSchema(name="random", dtype=DataType.DOUBLE),
FieldSchema(name="chunk", dtype=DataType.VARCHAR, max_length=2048),
FieldSchema(name="embeddings", dtype=DataType.FLOAT_VECTOR, dim=embeddings_model_dim),
#FieldSchema(name="embedding_model", dtype=DataType.VARCHAR, max_length=50),
]
schema = CollectionSchema(fields, "hello_milvus is the simplest demo to introduce the APIs")
collection = Collection(collection_name, schema, consistency_level="Strong")
index_params = {
"index_type": "IVF_FLAT", # FLAT、IVF_FLAT、IVF_PQ、IVF_SQ8、ANNOY 和 HNSW
"metric_type": "L2",
"params": {"nlist": 128},
}
collection.create_index("embeddings", index_params)
logger.info(f"Dose not exists collection {collection_name}, has create it.")
else:
collection = Collection(collection_name)
collection.load()
return collection
其中的
index_params = {
"index_type": "IVF_FLAT", # FLAT、IVF_FLAT、IVF_PQ、IVF_SQ8、ANNOY 和 HNSW
"metric_type": "L2",
"params": {"nlist": 128},
}
就是之前提到的向量索引的配置,index_type表示采用索引的类型,要根据数据集的大小和使用场景进行选择,一般数据量较小可以采用全量暴力检索FLAT可以提高搜索精度,如果数据量很大可以采用IVF_FLAT在精度和搜索效率上做个权衡。metric_type检索时使用的相似度算法,可选的有L2(欧几里德距离)、IP(内积)
、COSINE(余弦相似度),注意不同的index_type可能支持的metric_type略有不同,params是不同的index_type下的扩展参数,例如这里选的IVF_FLAT,params中的nlist则表示将数据集预处理成多少个聚类,每个聚类有一个聚类中心,当要检索目标输入时直接到与之最相近的聚类中查找即可,详细的参数配置和说明请参考官方文档详细说明:https://milvus.io/docs/index.md
数据管理
输入插入
def save_to_milvus(self, embedding_result: []):
collection = self.get_milvus_collection()
# 这里是个二维数组,第一维度对应集合中的每一个字段定义,除了自增的字段之外都要有相应的值
entities = [
[embedding_result[i]["doc_id"] for i in range(len(embedding_result))], # field doc_id
[float(random.randrange(-20, -10)) for _ in range(len(embedding_result))], # field random
[embedding_result[i]["chunk"] for i in range(len(embedding_result))], # field chunk
[embedding_result[i]["embeddings"] for i in range(len(embedding_result))], # field embeddings
]
insert_result = collection.insert(entities)
logger.info(f"insert_result {insert_result.primary_keys}")
# After final entity is inserted, it is best to call flush to have no growing segments left in memory
collection.flush()
数据删除
def delete_embeddings(self, doc_ids: [int]):
collection = self.get_milvus_collection()
while True:
query_res = collection.query(expr='doc_id in ' + str(doc_ids), output_fields=["id"], limit=30)
if len(query_res) == 0:
logger.warning(f"Delete_embeddings entity is empty: doc_ids:{doc_ids}")
break
ids = []
for i in range(len(query_res)):
ids.append(query_res[i].get('id'))
res = collection.delete(expr='id in ' + str(ids))
logger.info(f"Delete_embeddings success: doc_ids:{doc_ids}, res: {res}")
collection.flush()
查询数据
查找与目标字符串相近的字符串chunk
def search_embeddings(self, doc_ids: [int], intput_text: str, top_k: int = 3):
collection = self.get_milvus_collection()
vectors_to_search = self.get_embeddings_obj().embed_query(intput_text)
logger.info(f'search {intput_text} vectors success.')
search_params = {
"metric_type": "L2",
"params": {"nprobe": 128},
}
search_result = collection.search([vectors_to_search], "embeddings",
search_params,
limit=top_k,
output_fields=["chunk", "id"],
expr='doc_id in ' + str(doc_ids)
)
logger.info(f'{intput_text} search_embeddings_result>>> {search_result}')
result = []
max_distance = 1
if len(search_result) == 0:
logger.warning(f"{intput_text} search_embeddings_result is empty!!!")
return result
for i in range(len(search_result[0])):
hit = search_result[0][i]
distance = float(hit.distance)
# if distance > float(max_distance):
# continue
chunk = hit.entity.get('chunk')
id = hit.entity.get('id')
result.append({'chunk':chunk, 'chunk_id':id, 'distance':distance})
logger.info(f"{distance} chuck {chunk}")
return result


