这是我年初在公司内部技术分享讲Disruptor的PPT,整理下放到博客里面。
什么是Disruptor
Disruptor 是一个用于在线程间通信的高效低延时的消息组件,它像个增强的队列,能够在无锁的情况下实现异步并发操作,它是纯内存组件。
它的特点如下:
- 高性能、无锁,实现每秒千万级别的异步业务处理能力
- 它除了能实现队列基本功能,还能实现顺序消费,或者复杂的并行和依赖结合的消费方式
- 能实现一对多、多对一、多对多的广播或抢占试消费
为什么高性能,快速???
- 使用RingBuffer数据结构,实现内存复用,减少重新分配空间带来的时间空间损耗
- 使用CPU底层CAS(Compare And Swap :比较并交换)指令和内存屏障实现读写无锁化,并使用读写指针序列缓存行补齐方式达到真正的读写分离
- 阻塞等待策略,使用Busy Spin(疯狂死循环),是多核架构最快的通讯方式,同时也是最耗cpu的通讯方式,典型的牺牲硬件来换取速率
Disruptor数据结构
Disruptor底层是一个固定大小的环形数组,每个读或写线程自己维护一个可读可写序列对象Sequence,并保证每个序列在不同的内存缓存行中(cache line),避免伪共享,实现真正的无锁的读写分离,如图:
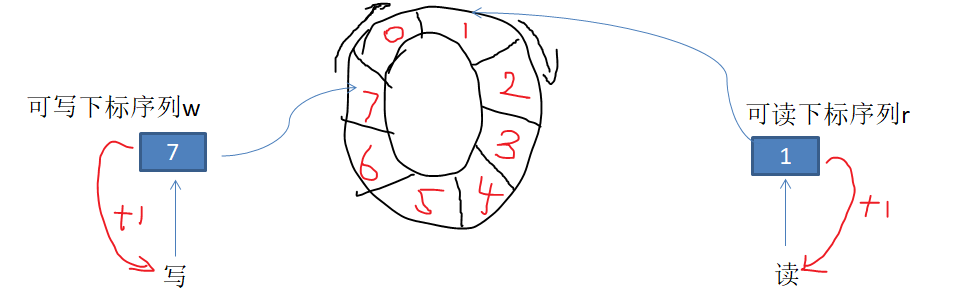
假设环形数组长度为L=8
当生产者写入一个元素时,对应写的Sequence下标w++;
当消费者读取一个元素时,对应读的Sequence下标r++;
当且r < w < r+L时,数组正常写入及消费
当且w=r时,数组为空,消费者阻塞,生产者可以从w+1%L的位置开始重复写入
当且w=r+L时,数组写满,生产者阻塞,消费者可以从r+1%L的位置开始读取
关于缓存行伪共享
我们知道CPU为了加快访问内存数据,设置了很多CPU高速缓存,当CPU要访问一个内存数据时,先从主内存中缓存一个Cache Line(缓存行,CPU高速缓存存取数据的最小单位是一个缓存行,Hotspot JVM最小单位是64字节,而有的是128字节,不同虚拟机对此处理不一样),而当一个缓存内的某个变量值改变时,其他缓存了此变量相邻的变量也将将失效,因为它们在一个缓存行中。这就是所谓的内存伪共享,虽然两个线程引用的变量不同,但是由于使用的是同一个缓存行的变量,也将受影响,从而影响CPU的执行速率。
在Disruptor中,为了实现真正的读写分离互不影响,也就是用于读写分离的两个Sequence对象使用缓存行填充的“笨方法”来避免这种伪共享。实现的方法就是将一个Sequence对象填充满一个缓存行,而避免其他无关的对象变量影响其使用速率。
实现原理:
我们知道一个在Java中一个对象的在内存中的大小取决于这个对象的成员变量大小,如下
需要使用一个long类型的成员变量value,一个long类型是8个字节,除了这个long类型value的下标外,定义14个long类型的变量p1、p2…p15,再加上一个对象的对象头大小是8字节,所以最终一个对象在在内存中的大小刚好是128字节,如果是64字节的 Line Cache就占用两个缓存行,128字节的Line cache就占用一个缓存行,在多线程情况下,排除了无关对象对这个Sequence对象的更新缓存失效影响。由于JDK7开始JVM会对对象的无效变量(未使用的变量)作优化处理,这里使用继承的方式,否则这种方式的缓存行填充是无效的,从JDK8开始已经原生支持缓存行填充,只需要一个注解:

@Contended
public class VolatileLong {
public volatile long value = 0L;
}
并且在java启动参数中设定
XX:-RestrictContended,@Contended注释才会生效。
Disruptor的其他特性
Disruptor 并行消费的结果依赖(等待)
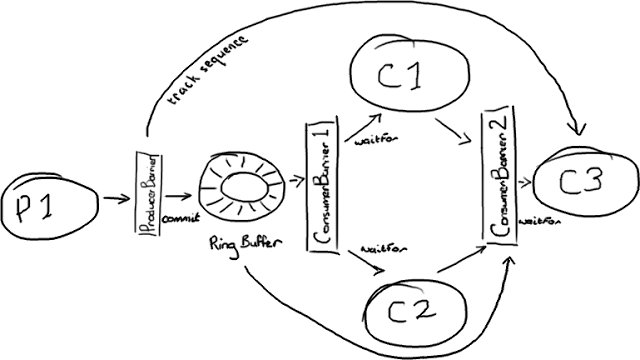
从中图可以看出需求是介样子的:生产者生产数据经过C1,C2处理完成后再到C3。
假设如下场景:
1、交易网关收到交易(P1)把交易数据发到RingBuffer中,
2、负责处理增值业务的消费者C1和负责数据存储的消费者C2负责处理交易
3、负责发送JMS消息的消费者C3在C1和C2处理完成后再进行处理。
使用以下代码就可以实现:
disruptor.handleEventsWith(new EventHandleOne(),new EventHandleTow()).then(new EventHandleThree());
Disruptor与ArrayBlockingQueue、LinkedBlockingQueue的比较
| ----- | Disruptor | ArrayBlockingQueue | LinkedBlockingQueue |
|---|---|---|---|
| 实现原理 | 固定大小的环形的ringbuffer存放元素 | 固定大小的数组存放元素,通过插入、取出两个下标协同循环使用数组 | 用链表存放元素,大小不固定 |
| 锁 | 无锁,多生产者之间有sequence竞争,采用比锁轻量的CAS操作 | 有锁,且读和写是同一个锁,锁粒度最大 | 有锁,读锁和写锁分开 |
| gc | 元素重用,gc较少 | 元素重用,gc较少 | 元素不重用,gc较多 |
| 其他 | 考虑cpu cacheline,避免false sharing,多种等待策略,可根据具体情况选用。比如自旋、wait、自旋一定时间然后wait等。 | 等待时线程wait,条件满足时,notify,线程切换较多 | 等待时线程wait,条件满足时,notify,线程切换较多 |
| 适用场景 | 1、性能最好2、消费者其实是一种广播的方式,即每个元素,每个消费者都要消费 | 1、多并发时性能不好。2、典型消费者-生产者模式,一个元素只给一个消费者消费 | 1、并发性比ArrayBlockingQueue好,但gc较多。2、典型消费者-生产者模式,一个元素只给一个消费者消费 |
| 一对一消费 | 16,355,904 tps/sec | 4,641,233 tps/sec | 4,633,706 tps/sec |
| 三对一消费 | 15,499,070 tps/sec | 8,055,421 tps/sec | 5,997,361 tps/sec |
| 10对一消费 | 17,624,251 tps/sec | 4,310,716 tps/sec | 5,670,863 tps/sec |
| 100对一消费 | 16,952,026 tps/sec | 537,634 tps/sec | 5,701,254 tps/sec |
| 10000对1消费 | 10,060,362 tps/sec | 84,906 tps/sec | 5,252,101 tps/sec |
大家感兴趣可以运行测试代码,Disruptor 性能测试代码:https://github.com/okeeper/disruptorTest.git
总结
凡事都不是选最好的,而是要选适合自己的。
同样,我们系统也要根据我们业务需要选择适合的技术。Disruptor,总结就是:如果非业务性能特殊需要,无必要使用Disruptor,如每秒600万订单处理,大多时候我们的JDK5的java.util.concurrent包已经够我们使用了,因为Disruptor会增加我们的成本(学习成本、维护成本以及硬件资源消耗)。


